

PythonからWordの文章や画像を読み込んだり、逆に文章を書き込んだりするにはpython-docxを使います。
ここではpython-docxの使い方を解説します。
python-docxのインストール
python-docxは標準でインストールされていないので、pipを使ってインストールしましょう。
$ pip install python-docxWordファイルの新規作成
新規にWordファイルを作成する場合はDocument()を使います。
import docx
doc = docx.Document()
print(type(doc))
doc.save('./output.docx')
[出力結果]
<class 'docx.document.Document'>python-docxを使うためにimport docxをインポートしています。
インポートしたdocxライブラリのDocument()で新規のドキュメントを作成し、save()で指定したパスへWordファイルを保存しています。
結果を見てわかる通り、作成したドキュメントはDocumentというクラスのインスタンスです。
Wordファイルへの読み込み
すでに作成済みのWordファイルの読み込みをしたい場合は、先ほど使用したDocument()の引数に読み込みたいWordファイルのパスを指定します。
今回はこちらのファイルを読み込み、タイトルを取得してみましょう。
[python-docx_sample.docx]
走れメロス
太宰治
メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。
メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊と遊んで暮して来た。けれども邪悪に対しては、人一倍に敏感であった。
きょう未明メロスは村を出発し、野を越え山越え、十里はなれた此このシラクスの市にやって来た。
メロスには父も、母も無い。女房も無い。十六の、内気な妹と二人暮しだ。
この妹は、村の或る律気な一牧人を、近々、花婿はなむことして迎える事になっていた。結婚式も間近かなのである。
メロスは、それゆえ、花嫁の衣裳やら祝宴の御馳走やらを買いに、はるばる市にやって来たのだ。
import docx
doc = docx.Document('./python-docx_sample.docx')
#段落を取得する
print(doc.paragraphs[0].text)
[出力結果]
走れメロス段落のテキストはparagraphsのリストから取得します。
paragraphsには段落の情報がリスト形式で格納されています。今回はタイトルを取得したいので、最初の1つ目の段落を[0]を指定して取得しています。
段落数が知りたい場合はlen()にparagraphsを渡すことで解決できます。
全段落のテキストを取得する
全段落のテキストを取得したい場合はparagraphsをループさせます。
for paragraph in doc.paragraphs:
print(paragraph.text)
[出力結果]
走れメロス
太宰治
メロスは激怒した。必ず、かの邪智暴虐の王を
<中略>
はるばる市にやって来たのだ。
runsからフォントサイズとフォント名を取得する
runsは段落内のある一区間に適用されているスタイルの情報がリスト形式で格納されているインスタンスです。
例えば次のような文章があるとしましょう。
「私の名前はみゃふです。」
この文章だとrunsには「私の名前は」「みゃふ」「です。」に分かれて格納されます。「みゃふ」のみ太字+色を付けているので、この部分で情報が分割されています。
補足として、Wordではかな+漢字とローマ字の間でもrunsは分割されます。
今回はこのrunsからタイトルと著者名のフォントサイズと、タイトルのフォント名を取得してみましょう。
タイトルと著者名は1つのrunで構成されているので、runs[0]を指定することでそれぞれ取得できます。
import docx
doc = docx.Document('./python-docx_sample.docx')
#タイトルのフォントサイズとフォント名(1段落目、1つ目のrun)
title = doc.paragraphs[0]
print(f"タイトル フォントサイズ={title.runs[0].font.size / 12700}")
print(f"タイトル フォント名={title.runs[0].font.name}")
#著者名のフォントサイズ
author = doc.paragraphs[1]
print(f"著者名 フォントサイズ={author.runs[0].font.size / 12700}")
[出力結果]
タイトル フォントサイズ=26.0
タイトル フォント名=Arial Unicode MS
著者名 フォントサイズ=16.0
フォントサイズはruns[0].font.sizeで取得できます。実際に指定したフォントサイズ × 12700の数字が返ってくるので、12700で割ることで分かりやすくなります。
また、フォント名はruns[0].font.nameで取得できます。
画像を取得する
Wordファイル内の画像を取得する場合はWordファイルをzip化する必要があります。
import zipfile
docx_path = './python-docx_sample.docx'
docx_zip = zipfile.ZipFile(docx_path)
zipped_files = docx_zip.namelist()
print(zipped_files)
for file in zipped_files:
if file.startswith("word/media/"):
img_file = docx_zip.open(file)
img_bytes = img_file.read()
# 画像ファイルの保存
with open('./image.png', 'wb') as f:
f.write(img_bytes)
img_file.close()
docx_zip.close()
print('画像を保存しました。')
[出力結果]
['word/numbering.xml', 'word/settings.xml', <中略> 'word/media/image1.png', '[Content_Types].xml']
画像を保存しました。
WordファイルをZipFileでzip化し、namelist()で中身を取り出すと、word/mediaから始まる
アーカイブメンバがいるのが分かります、これが画像ファイルです。
あとはアーカイブメンバをループさせてword/mediaから始まるファイルのみ抽出し、with openで所定の位置に画像を保存しています。
Wordに書き込む
今度は書き込みのやり方を解説します。
単純にWordに文章を書き込みたい場合はadd_paragraph()を使います。
新しいファイルを作って段落を作成してみましょう。
import docx
doc = docx.Document()
doc.add_paragraph('走れメロス')
doc.save('./output.docx')
[出力結果]
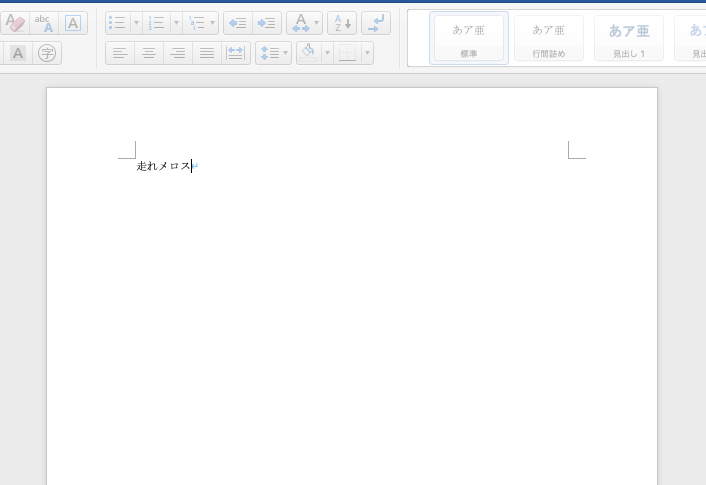
新しくoutput.docxファイルを作成し、最初の段落にタイトルを追加しました。
add_paragraph()を追加していくことで次の段落へ文章を追加していくことができます。
import docx
doc = docx.Document()
doc.add_paragraph('走れメロス')
doc.add_paragraph('太宰治')
doc.add_paragraph('メロスは激怒した。必ず...')
<中略>
doc.add_paragraph('...はるばる市にやって来たのだ。')
doc.save('./output.docx')
[出力結果]
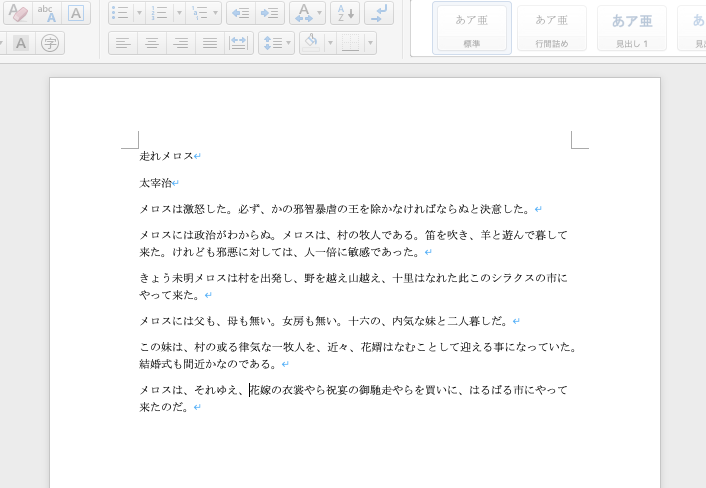
フォントサイズを変える
フォントサイズを変える場合はrunのスタイルを変える必要があります。
タイトルと著者名のフォントサイズをそれぞれ26pt、16ptに変更してみましょう。
import docx
doc = docx.Document('./output.docx')
#タイトル
doc.paragraphs[0].runs[0].font.size = docx.shared.Pt(26)
#著者名
doc.paragraphs[1].runs[0].font.size = docx.shared.Pt(16)
doc.save('./output.docx')
[出力結果]
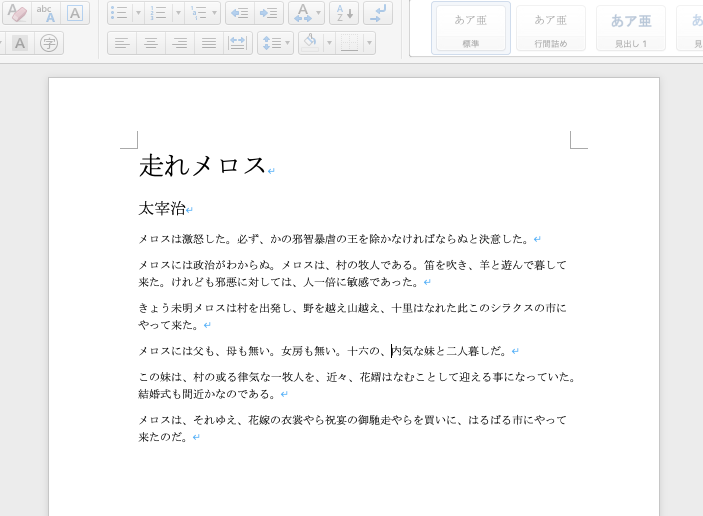
画像を挿入する
画像を挿入する場合はadd_picture()を使います。
import docx
doc = docx.Document('./output.docx')
doc.add_picture('./image.png')
doc.save('./output.docx')
[出力結果]
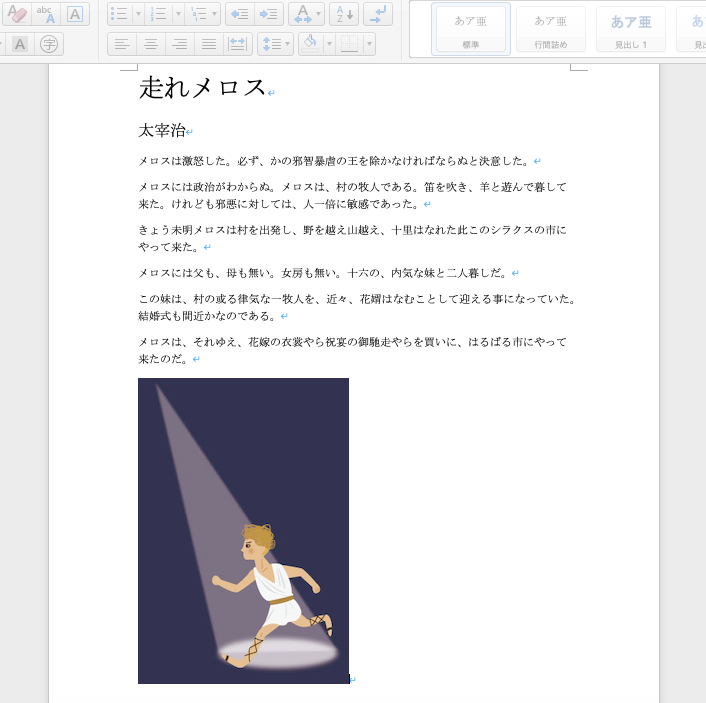
段落の最後に追記する
すでに存在する段落の最後に文章を追記したい場合はparagraphs[]で段落を指定したあとにadd_run()を使います。
import docx
doc = docx.Document()
doc.add_paragraph('段落1:')
doc.add_paragraph('段落2:')
doc.add_paragraph('段落3:')
#段落2に追記する
doc.paragraphs[1].add_run('追記しました')
doc.save('./output2.docx')
[出力結果]

改行する
改行したい場合はadd_break()を使います。add_break()はrunインスタンスのあとに使い、段落内の好きなところで改行できます。
import docx
doc = docx.Document()
doc.add_paragraph('私は')
doc.paragraphs[0].add_run('刺身が')
doc.paragraphs[0].add_run('好きです。')
#改行
doc.paragraphs[0].runs[1].add_break()
doc.save('./output3.docx')
[出力結果]
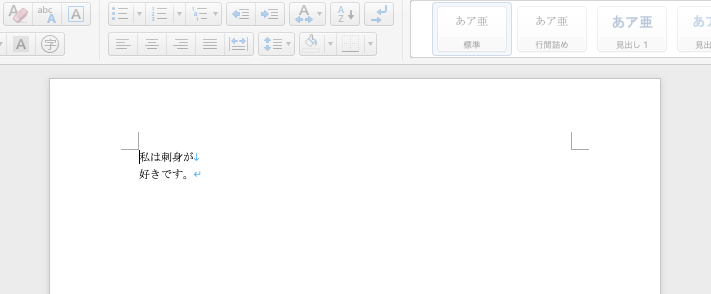
add_run()で文章を追記しているので、1つの段落に3つのrunが存在しています。
その内2つ目のrunの後に改行を追記しています。
改ページする
改ページはadd_page_break()を使います。
import docx
doc = docx.Document()
doc.add_paragraph('吾輩は')
doc.add_page_break() #改ページ
doc.add_paragraph('猫である。')
doc.save('./output4.docx')
[出力結果]1ページ目
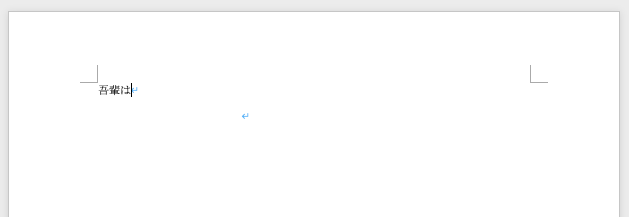
2ページ目




