

PythonのライブラリPyocrを使い、OCR処理が出来るプログラムを作成してみようと思います。OCRとは『光学的文字認識』の意で、画像中に表示されている文字情報を抽出し、テキストデータへ変換する技術のことです。最近はAI OCRが有名ですね。
もっとも今回はPythonだけではなく、Googleが公開しているOCRエンジン・Tesseractを組み合わせて作ります。
なおOSはWindowsです。
記事の前半でプログラムの作り方を、後半で実際にレシート画像の文字を抽出してみたので、最後までお読みいただけると嬉しいです!
ライブラリとTesseractのインストール
全体のコードの解説に入る前に、まず今回使用するライブラリの紹介をします。以下のコードでライブラリ等をインストールしてください。
pip install pillow
pip install pyocr
tesseract-ocr-w64-setup-v5.0.0-rc1.20211030.exe
ライブラリ Pillow
PillowはPythonの画像処理を行うライブラリです。同様のライブラリとしてはOpenCVが有名ですが、OpenCVと違って画像の大きさ(トリミング)や輝度、コントラストの変更といったよりシンプルな処理を行うことに特化しています。画像の情報も取得できるので、画像に関するプログラムを実装するのに不可欠なライブラリとなっています。
ライブラリ Pyocr
PyocrはPythonのOCRのライブラリで、Tesseract(OCRツール)を利用できます。TesseractはGoogleが公開したOCRエンジンでGitから無料でダウンロードが可能で、Tesseractを利用することで画像に表示されている文字を抽出することが出来ます。
exeファイルがダウンロードされるので、インストールをします。
Tesseractのインストール方法
起動させたらそのままNextをクリックして進めてください。
Choose Componentsになったら、Additional script dataとAdditional language dataで日本語に関するデータ(『Japanese script』と『Japanese vertical script』)を選択してダウンロードしてください。
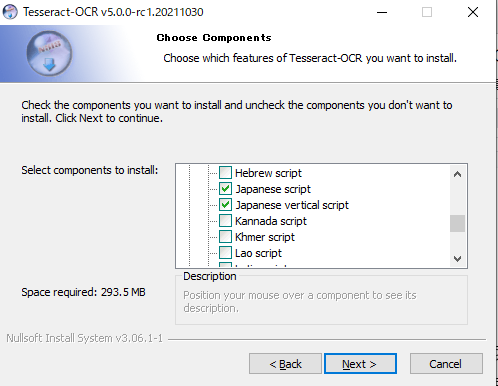
その次でも同じ項目を選択してください。
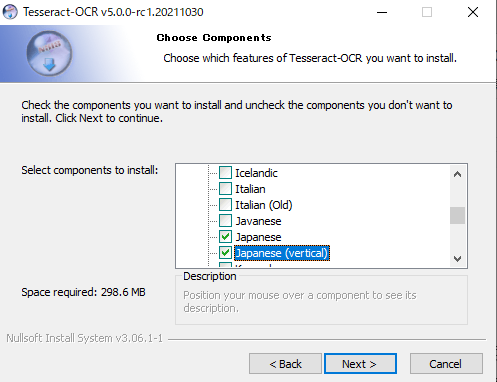
Nextをクリックし、インストールが完了したらTesseractの設定はOKです。
いよいよ次からコードを紹介していきます!
全コードの紹介
まず初めに全コードを紹介します。
import os
from PIL import Image
import pyocr
#環境変数「PATH」にTesseract-OCRのパスを設定。
#Windowsの環境変数に設定している場合は不要。
path='C:\\Program Files\\Tesseract-OCR\\'
os.environ['PATH'] = os.environ['PATH'] + path
#pyocrにTesseractを指定する。
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
#文字を抽出したい画像のパスを選ぶ
img = Image.open('画像のパス/画像の名前.JPG')
#画像の文字を抽出
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
text = tool.image_to_string(img, lang="jpn", builder=builder)
print(text)
画像のパスを実行する環境に合わせれば実行できるはずです。
全体のコードの解説
では、各項目について細かく見ていきましょう。
ライブラリのインポート
import os
from PIL import Image
import pyocr
最初の三行でライブラリを読み込みます。
環境変数の設定
path='C:\\Program Files\\Tesseract-OCR\\'
os.environ['PATH'] = os.environ['PATH'] + path
インストールしたTesseractを環境変数に設定するソースを記載します(Windowsの設定からTesseractの環境変数を設定している場合このコードは不要)。
PyocrにTesseractのパスを指定
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
pyocr.tesseract.TESSERACT_CMDには実際にtesseract.exeが保存されているパスを設定してください。tesseract.exeのパスが間違えているとtools[0]に何も入っていない事になってしまい、エラーの原因となります。
画像ファイルのパス指定
img = Image.open('画像のパス/画像の名前.JPG')imgに文字を抽出したい画像のパスをセットします。
読み取り精度の設定
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
text = tool.image_to_string(img, lang="jpn", builder=builder)
tesseract_layoutは読み込みの精度を調節するプロパティで、0から10までの値を設定できます。今回は文字一つ一つをブロックとして認識する6にしました。
二行目で画像、日本語である事、精度のプロパティを、OCRエンジン(tool)に投げます。
認識した文字の表示
print(text)投げた結果をprintで表示させます。
実際にOCRを試してみた
今回作ったコードで、下記画像のレシートの文字を抽出させてみました。
レシートを撮影し、画像にOCRをかけてみます。

文字の抽出結果
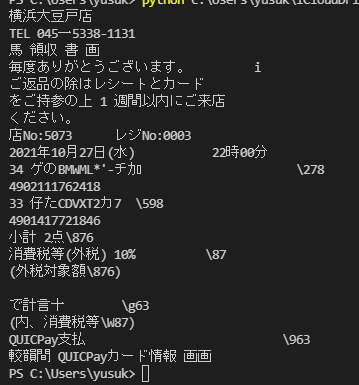
レシートから文字を抽出することに成功しました。概ね数字はほぼ完璧に認識できているようですが、レシート特有の半角のカタカナや、画数の多い漢字の読み込みは少し厳しいようです。逆に『■』のような記号は漢字として認識してしまいました。また、『\』は一律でバックスラッシュとして吐き出されています。
文字認識の精度を上げる方法
Tesseractの日本語のデータは抽出速度を優先しているので、精度を重視したファイルをダウンロードし、画像から文字を抽出してみました。
上記ファイルを「C:/Program Files/Tesseract-OCR/tessdata」に上書き保存してください。既にあるファイルはバックアップとして保存しておきましょう。
print(text.replace('\\','¥'))そして最後のprintで置換を行い、バックスラッシュで表示されてしまう部分を¥に置換させてみました。
精度を上げる日本語ファイルで実行してみた
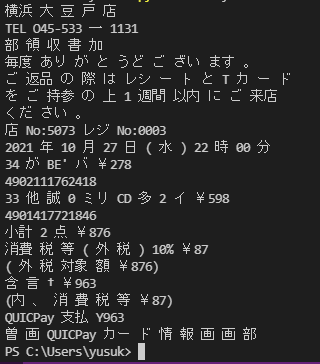
少し悪化した所と、改善されたところがありますね。『\』が全て置換されていることが分かります。
レシートに出力されているカタカナが半角なので、ここが漢字の部首として認識されてしまうようです。Tesseract_layoutのプロパティを変更しても認識度を上げることは出来ませんでした。
結果
カタカナの半角の認識は現段階の認識力では厳しいようです。一方画数の多い漢字はしっかり認識できるようになりました。
今回はPyocrを使った基本的なOCRを作ってみました。今回は業務レベルで使うのは厳しい精度だったかもしれませんが、画像を白飛ばししたり機械学習を取り入れたりすることでより高精度に出来るかも知れません。皆さんも是非色々試してみてくださいね。



