

取引先との契約書をパスワード付きのPDFで受け取ったが、パスワードが記載されたメールを誤って削除してしまった…そんなこと、起こらないに越したことはありませんが、万が一起きてしまっても挽回する方法があります。パスワードが分からない状態でも、Pythonのライブラリを使うことでPDFのパスワードを解除するプログラムを作れるのです。
今回はパスワード設定されたファイルを総当たりで解除するプログラムを解説していきます。他サイトだとZIPファイルのパスワードを解除するプログラムが多いので、今回はPDFで試してみようと思います。
使用するライブラリ“Pikepdf”
pip install pikepdf今回はパスワード解除によく用いられるPikepdfで作ってみます。
他にパスワード解除に使われるライブラリとしてpypdfもありますが、pypdf2ではRC4と呼ばれるセキュリティ面で脆弱なパスワードにしか対応していません。一方今回のPikepdfはアメリカで暗号化の標準規格として採用されているAESも対応しています。
最近のソフトの多くはAESに対応しているため、パスワード解除にはPikepdfを利用することをお勧めします。
実際にMacのプレビューソフトでPDFにパスワードをかけ、その後Pythonでパスワードを総当たりしてみところ、pypdf2ではセキュリティに関するエラーが発生してしまいましたが、Pikepdfはしっかりとパスワードを解析できました。
それではコードを見ていきましょう!
全体コードの紹介
import pikepdf
import itertools
import sys
#パスワードがかけられているPDFファイル
pdf_lock = r'C:\パスワードが設定されてるPDFまでのパス\lock.pdf'
#パスワード解除後のPDFファイル
pdf_nolock = r'C:\パスワード解除したPDFを保存するパス\no_lock.pdf'
#パスワードの確認に使用する文字
characters = [ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
#パスワードの桁数の設定
count = 0
#総当たり開始
while True:
count += 1
for password in itertools.product(characters,repeat=count):
try:
#パスワードの文字を結合
password = ''.join( password )
pdf = pikepdf.open(pdf_lock, password=password)
pdf_unlock = pikepdf.new()
pdf_unlock.pages.extend(pdf.pages)
pdf_unlock.save(pdf_nolock)
except:
print(password + ' は一致しませんでした')
else:
print('パスワードは' + password + 'でした。')
#処理終了
sys.exit()
今回のソースコードでは、小文字と数字を組み合わせてパスワードが解除できるまで処理をし続けるプログラムになっています。
それぞれのコードの解説
それでは各項目を詳しく解説します。
ライブラリのインポート
import pikepdf
import itertools
import sys
#パスワードがかけられているPDFファイル
pdf_lock = r'C:\パスワードが設定されてるPDFまでのパス\lock.pdf'
#パスワード解除後のPDFファイル
pdf_nolock = r'C:\パスワード解除したPDFを保存するパス\no_lock.pdf'
今回使用インストールしたPikepdfをインポート。itertoolsでループする際に文字を結合するために、sysでパスワードが解析できた場合にPythonを終了させるためのライブラリをインポートします。
6行目で総当たりさせたいPDF、8行目でパスワードを外したPDFを保存するパスを設定します。
総当たりに使用する文字の設定
#パスワードの確認に使用する文字
characters = [ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
11行目ではパスワードの総当たりで使用する文字を設定します。パスワードの解析はとても時間がかかるので、なるべく使用する文字を減らしておきましょう。パスワードに大文字を使用している場合は、大文字も追加しておきましょう。
総当たりの実行
パスワードの桁数の設定
count = 0
#総当たり開始
while True:
count += 1
for password in itertools.product(characters,repeat=count):
try:
#パスワードの文字を結合
password = ''.join( password )
pdf = pikepdf.open(pdf_lock, password=password)
pdf_unlock = pikepdf.new()
pdf_unlock.pages.extend(pdf.pages)
pdf_unlock.save(pdf_nolock)
except:
print(password + ' は一致しませんでした')
else:
print('パスワードは' + password + 'でした。')
#処理終了
sys.exit()
14行目でパスワードの桁を設定しますが、総当たりの前に数字を0に設定をしておきましょう。
ここからが総当たりの処理になります。17行目から無限ループを開始し、18行目でパスワードの桁数を一行ずつ増やしていきます。
19行目のrepeatでパスワードの桁数を設定し、charactersに入っているパスワード候補をpasswordに入れて全てのパターンを繰り返します。
20行目にtryを使い、実際にパスワードを解除していきます。パスワード解除でエラーが発生した際はパスワードが違うという事なので、28行目に流してパスワードが違うことをprintで表示しています。
22行目ではpasswordに入っている文字をjoin句でシングルクォーテーションで囲み、文字列としてpasswordに入れます。
24行目でpikepdfのopen関数の一つ目にパスワードがかかっているPDFのパス、2個めのパスにパスワーを設定します。
25行目では新しいPDFファイルを作成します。
26行目で新しいPDFファイルと、パスワード解除できたPDFを結合します。
最後にsaveでPDFファイルをpdf_nolockに入れたパスに保存し、30行目のelseに移動して実際に解除できたパスワード表示します。
33行目で全ての処理を中断し、無限ループを終了させます。
実際にやってみる
実際にパスワードの総当たりをしてみました。
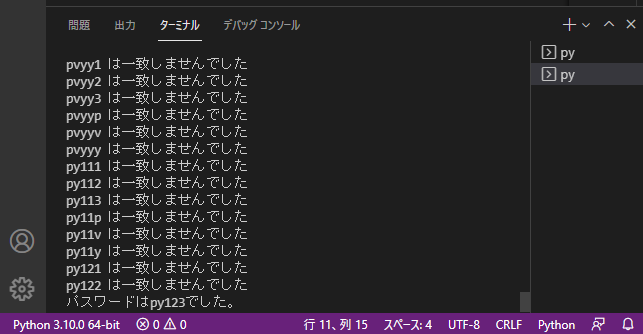
パスワードの総当たりには数時間かかってしまい、数字やアルファベットを全て設定すると非常に長い時間がかかってしまいます(使用するPCのスペックにも依存します)
実際に設定したpy123でPDFファイルを開き、パスワードが設定されないPDFの保存に成功しました。
Pikepdfでほかにできることはある?
今回はPikepdfでパスワード解除する方法を紹介してきましたが、他にできることを紹介します。
・ pikepdf._qpdf.PasswordError
無効なパスのエラーキャッチ。exceptで使用する事が条件。
PythonではPDFに書き込みやパスワード設定、メタデータの設定などがありますが、この場合基本的にはPyPDF2を利用します。
パスワード解除する際はPikepdfを使用した方がより解除できる可能性が増えるので、PDFのシステムを構築する際にはPikepdfとPyPDF2を併用すると良いでしょう。



