

Pythonで作れる代表的なプログラムとしてWebスクレイピングが挙げられます。これは主にライブラリを活用して実行するので、Pythonを覚えたての初心者でも簡単に作ることが出来ます。
今回はPythonを使い、Googleの検索結果に表示された記事のタイトル・URLをExcelに書き出すプログラムの作り方を紹介します。
Webスクレイピングとは?
Webスクレイピングとは、Web上のサイトから任意の情報を自動で取得する技術のこと。出したデータを加工してファイルとして出力したり、データベース上にデータを溜めることもできます。
一般的にはホームページから大量の情報を取得したい時に使われますが、今回のように検索エンジンの結果一覧にもスクレイピングを実行することが可能です。
ブログやホームページを運営するうえで欠かせない作業が、ターゲットキーワードによる検索結果の把握です。上位表示されている競合サイトは新しく記事を作成する上で必ずチェックが必要ですが、表示サイトを手作業で数十件集計するのはとても時間が掛かってしまいます。
ですが、検索結果の集計もWebスクレイピングがあればたった数秒で終わり、競合調査の大幅な効率化に繋がります。スクレイピングには規約があり、スクレイピングを禁止しているサイトもあるので注意が必要ですが、今回はGoogle検索結果自体をスクレイピングするプログラムなので、その点心配する必要はありません。
スクレイピングサービスやアプリはあるけど…
ちなみにプログラミングの知識が無くても、GoogleのスプレッドシートやWebスクレイピング専用ソフトであるOctoparseでも、スクレイピングができます。
Googleスプレッドシートにはスクレイピング専用の関数があり、実行するハードルはPythonより下がります。しかし処理スピードが遅い上、カスタマイズ性=自分の望む仕様にすることが出来ない為、自作の方がより高機能な抽出をすることができます。
またOctoparseについては、無料版だと一回のスクレイピングできる量が10,000件と制限がかけられていたり、こちらも自分の好きなようにカスタマイズできないといったデメリットがあります。 初心者レベルだとしても、Pythonを少し学んだ方なら是非プログラミングで実行してみることをおすすめします。
今回やりたいこと
今回はPythonの実行で指定のキーワードで検索し、検索結果の上位50件のデータをExcelファイルに書き出し→保存して閉じるところまで実装してみようと思います。
スクレイピングのライブラリ“Selenium”を使う
今回はSeleniumというライブラリを使用するので、まずインストールしましょう。
pip install seleniumBeautifulSoupとの違いは?
WebスクレイピングのライブラリといえばBeautifulSoupでは?と思われるかもしれません。事実本稿で行うGoogle検索結果のスクレイピングでも、SeleniumではなくBeautifulSoupを使って解説している記事がいくつかあります。そのためまず、BeautifulSoupとSeleniumの違いについて簡単に説明しておきましょう。
SeleniumはWebブラウザのオートメーションツールなので、プログラムを実行するとWebブラウザが立ち上がり、プログラムによってWebブラウザが操作されます。
一方のBeautifulSoupは指定したURLのHTMLを抽出し、そのデータから任意のデータを抽出するものです。つまり、SeleniumはWebブラウザを起動させてから様々なプログラムを組むもので、BeautifulSoupは直接データを抽出するもの、という違いがあるのです。
Google検索結果を取得するにはキーワードを入力→抽出するという操作が必要なので、Seleniumが適しているんですね。
Seleniumを使うにはWebDriverを使う必要があります。
こちらの記事を参考にダウンロードしましょう。
今回はChromeを使いスクレイピングを進めていきます。検索ワード「猫 喋る なぜ」の検索上位50件を一気に取得してみましょう!
全コードの紹介
import openpyxl
import time
from selenium import webdriver
#googleで検索する文字
search_string = '猫 喋る なぜ'
#Seleniumを使うための設定とgoogleの画面への遷移
INTERVAL = 2.5
URL = "https://www.google.com/"
driver_path = "./chromedriver"
driver = webdriver.Chrome(executable_path=driver_path)
driver.maximize_window()
time.sleep(INTERVAL)
driver.get(URL)
time.sleep(INTERVAL)
#文字を入力して検索
driver.find_element_by_name('q').send_keys(search_string)
driver.find_elements_by_name('btnK')[1].click() #btnKが2つあるので、その内の後の方
time.sleep(INTERVAL)
#検索結果の一覧を取得する
results = []
flag = False
while True:
g_ary = driver.find_elements_by_class_name('g')
for g in g_ary:
result = {}
result['url'] = g.find_element_by_class_name('yuRUbf').find_element_by_tag_name('a').get_attribute('href')
result['title'] = g.find_element_by_tag_name('h3').text
results.append(result)
if len(results) >= 50: #抽出する件数を指定
flag = True
break
if flag:
break
driver.find_element_by_id('pnnext').click()
time.sleep(INTERVAL)
#ワークブックの作成とヘッダ入力
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet['A1'].value = 'タイトル'
sheet['B1'].value = 'URL'
#シートにタイトルとURLの書き込み
for row, result in enumerate(results, 2):
sheet[f"A{row}"] = result['title']
sheet[f"B{row}"] = result['url']
workbook.save(f"google_search_{search_string}.csv")
driver.close()
上記コードを走らせるとGoogle検索で「猫 喋る なぜ」を検索し、上位50件のページタイトルとURLを取得し、CSVファイルとして保存します。
コードの解説
それでは少しずつ解説していきます。
ライブラリのインポート
import openpyxl
import time
from selenium import webdriver
今回はExcelファイルを操作するOpenpyxlと今回紹介するSeleniumを使うので、それぞれインポートしています。
また、timeモジュールはGoogleが画面遷移するタイミングで処理をスリープするために使っています。
検索ワードの指定
search_string = '猫 喋る なぜ'search_stringにはGoogleで検索する文字列を入力しています。
Googleの操作
INTERVAL = 2.5
URL = "https://www.google.com/"
driver_path = "./chromedriver"
driver = webdriver.Chrome(executable_path=driver_path)
driver.maximize_window()
time.sleep(INTERVAL)
driver.get(URL)
time.sleep(INTERVAL)
INTERVALには処理をスリープする際の秒数を、URLにはGoogleのURLを格納しています。
driver_pathにはchromedriverのパスを格納しています。それぞれの環境で異なってくる部分ですが、ソースコードと同じにする場合はこのプログラムと同じ階層にchromedriverを配置しましょう。
webdriver.Chrome関数にchromedriverを渡して、プログラム側からブラウザを操作するために必要なdriverを作成し、そのdriverとURLを使ってchromeでgoogleのサイトを開いています。
もしchromedriverが正しく認識されない場合は、下記のソースに書き換えてみてください。
import chromedriver_binary
~省略~
#driver_path = "./chromedriver"
#driver = webdriver.Chrome(executable_path=driver_path)
driver = webdriver.Chrome()
~省略~
driver_pathにパスを指定するのではなく、chromedriver_binaryをインポートすることで、webdriver.Chrome()でドライバーの場所を取得してくれます。
直接ドライバーのパスを指定しても動作しない場合は、上記を試してみてください。
検索の実行
driver.find_element_by_name('q').send_keys(search_string)
driver.find_elements_by_name('btnK')[1].click()
time.sleep(INTERVAL)
Googleの画面を開いた後、name属性が’q’の要素に検索文字列を入力しています。’q’は検索テキストボックスです。
次に’btnK’をクリックしています。’btnK’は検索ボタンです。’btnK’のname属性を持つ要素は2つあるので、そのうち最後の方をクリックしています。
クリックすることで検索が走ります。
各ページタイトルとURLの取得
#検索結果の一覧を取得する
results = []
flag = False
while True:
g_ary = driver.find_elements_by_class_name('g')
for g in g_ary:
result = {}
result['url'] = g.find_element_by_class_name('yuRUbf').find_element_by_tag_name('a').get_attribute('href')
result['title'] = g.find_element_by_tag_name('h3').text
results.append(result)
if len(results) >= 50: #抽出する件数を指定
flag = True
break
if flag:
break
driver.find_element_by_id('pnnext').click()
time.sleep(INTERVAL)
while Trueで無限ループしつつ、件数が50件に到達したらループを抜けています。
g_aryは検索結果のタイトルとURLが入った要素をリストで保持しています。
それをfor inでループし、タイトルとURLを中から取り出してresult辞書に格納後、resultsに一つずつ渡しています。
条件分岐の50の部分を変更することで、取得する件数を変更できます。
タイトルはh3タグのtextから、URLはname属性が’yuRUbf’の要素の中のaタグのhref属性からそれぞれ取得しています。
Googleはアルゴリズムのアップデートにより検索結果の見え方が変わる可能性もあるので、検証ツールを利用してh3に使用されているクラスなどがプログラムと一致しているかを確認しましょう。
これで検索結果を50件分取得できました。次は取得したデータをexcelに書き出します。
Excelの作成と書き出し
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet['A1'].value = 'タイトル'
sheet['B1'].value = 'URL
Workbook()で新しいExcelファイルを作成しています。
新しく作成すると最初から「sheet」という名前のシートが作成され、そのシートがアクティブ状態になっているので、workbook.activeで「sheet」シートを取得します。
後はA1セルに「タイトル」B1セルに「URL」を書き込み、ヘッダを作成しています。
行の指定とファイル名付与、保存
for row, result in enumerate(results, 2):
sheet[f"A{row}"] = result['title']
sheet[f"B{row}"] = result['url']
workbook.save(f"google_search_{search_string}.csv")
driver.close()
先ほど取得した50件分のデータを繰り返し、Excleの2行目から順に書き込んでいます。
enumerateの2つ目の引数に2を指定することで、row変数は2からインクリメントされています。
全て書き終わったら最後にファイル名を決めて保存し、driver.close()でブラウザを閉じています。
これで処理は完了です。同じ階層に検索結果のExcelファイルが作成されるので、確認してみましょう。
workbook.save(r"C:\ディレクトリ\プログラム\Python\Selenium1" + f"\google_search_{search_string}.tsv")完全パスで指定したい場合は上記のように記述してください。
今回はcsvファイルで出力しましたが、.xlsxで出力したい場合は"\google_search_{search_string}.tsv"を"\google_search_{search_string}.xlsx"に変更してください。
実際に出力してみる
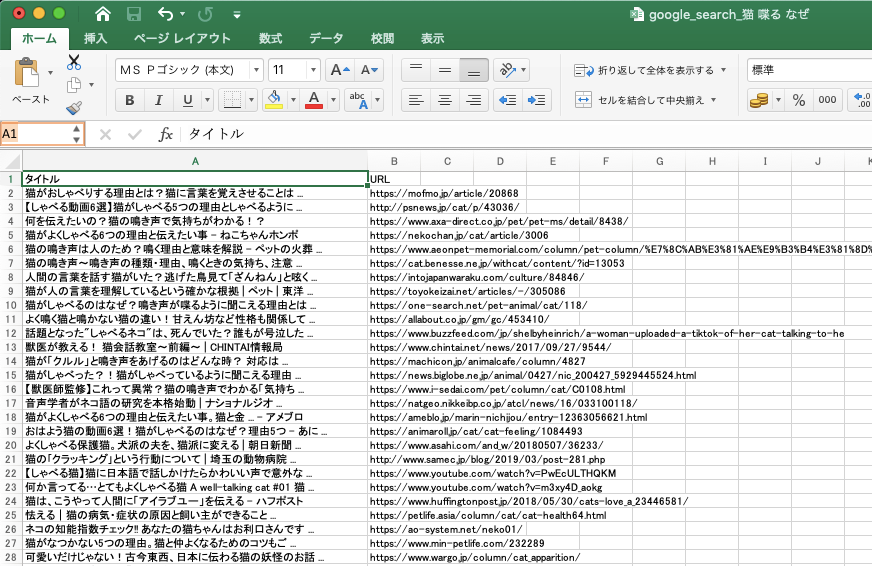
上記ソースで実行した結果は上記のようになりました。1行目はヘッダーなので、50件取得した場合は2列目から51列目までデータが表示されます。
より詳細なSEO対策の分析をする方法
今回はホームページ運営をするうえで大切な競合分析を半自動化するプログラムを紹介しました。
ですが、よりホームページのSEOを強化する場合はサイトのタグ、メタ情報、robot情報も収集し、対策を行わなければいけません。
SEOは細かい施策がたくさんありますが、一つ一つ丁寧に設定することでより流入数を増やせるブログとなります。
実際に上位表示されているサイトがどのように設定しているかを一瞬で調べる方法があれば、利用したくありませんか?
以下記事で、タイトルやURLLに加え、SEO対策に必要なメタディスクリプションやrobot情報、記事中で使われている見出しまで一気に抽出出来るプログラムを解説しています。本稿でWebスクレイピングに慣れた方は是非試してみてください。




