

PythonでスクレイピングをするにはrequestsやBeautiful Soupなどを使いますが、Seleniumを使う方法もあります。
Seleniumを使えばJavaScriptを使った動的なページにも対応できます。
ここでは「Seleniumって何?」「urllibやrequestsと何が違うの?」「Seleniumの使い方が知りたい」といった方へ、Seleniumについて解説します。
スクレイピングする際のルール
スクレイピングは他のサイトの情報を取得する行為なので、著作権法を守る必要があります。
こちらにスクレイピングするルールを載せていますので、スクレイピングする場合は以下の記事のスクレイピングをする際のルールをご一読ください。

Seleniumとは
今回はスクレイピングをする上でのSeleniumの紹介となりますが、Seleniumuは本来スクレイピングをするものとして作られたライブラリではなく「ブラウザをプログラムから操作し、テストを自動化する」目的で作られたものです(いわゆるオートメーションツール)。
しかし、ブラウザを操作する際にhtmlを取得することができるので、結果スクレイピングもできるようになっています。
また、Seleniumは人間と同じようにブラウザを操作できるので、やろうと思えばスクレイピングやテスト自動化以上のことも可能です。
今まで手作業で行なっていたことが、Seleniumを使うことで自動化することができます。
Seleniumとurllib、requestsの違い
上述したようにSeleniumはブラウザの自動操作ができるツールなので、urllibやrequestsのような、htmlを取得するライブラリよりも多くのことが可能です。
スクレイピングの観点で言えば、urllibやrequestsの場合は取得したhtmlをBeautiful Soupに通してから要素を取得するのが一般的ですが、Seleniumの場合はBeautiful Soupを通さずに要素を取得できます(Beautiful Soupを使うこともできます)。
また、Seleniumはブラウザを操作することができるので、JavaScriptを使った動的なページに対しても行うことが可能です。
Seleniumの使い方
では実際にSeleniumを使ってみましょう。
なお、今回はMacOS Mojave(10.14.6) + Google Chrome(80.0.3987.122)の環境で実行します。
特にGoogleChromeのバージョンは非常に重要なので、先に調べておきましょう。
左上のリンゴマークの隣のChromeをクリックして「Googe Chromeについて」を選択するとバージョン情報が表示されます。
Web Driverをインストールする
Seleniumを使うにはそのブラウザのWebDriverを使う必要があります。
このWebDriverはブラウザのバージョンと対応しているので、バージョンが合っていないとSeleniumはうまく動作してくれません。
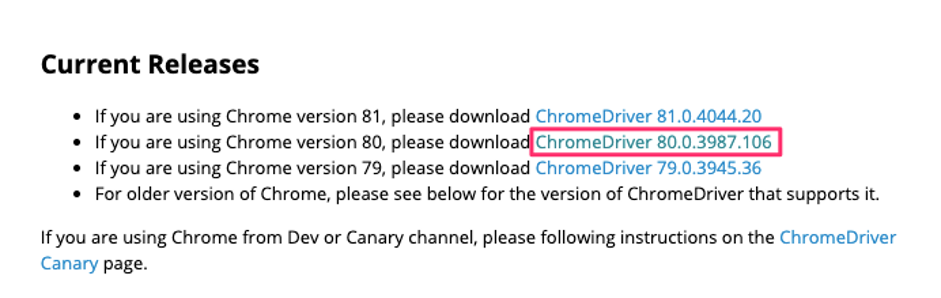
Chromeの場合はChromeDriverをダウンロードします。以下のURLからダウンロード画面へいけます。
今回はChrome80のバージョンを使っているので、真ん中のDriverを選択します。
すると次の画面が別タブで開くので、mac用のzipファイルをクリックします。
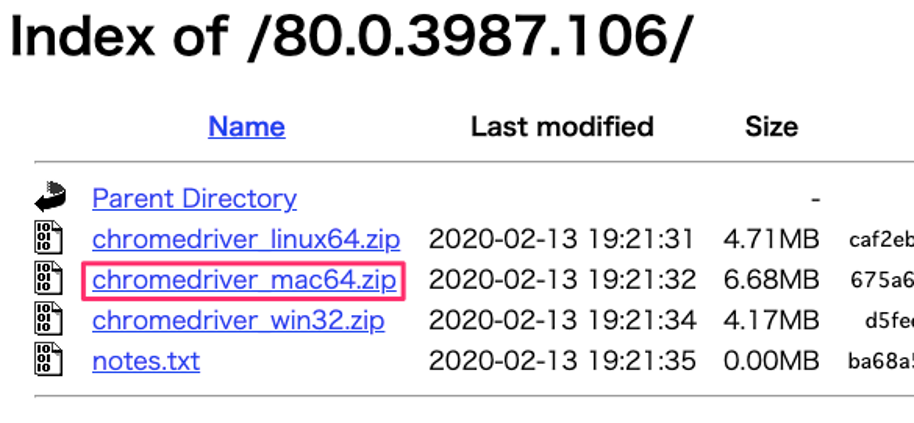
クリックするとダウンロードが始まるので、終わったらzipファイルを解凍します。
これでChromeDriverのダウンロードは完了です。
Seleniumでスクレイピングする
それではこれからSeleniumを使ってスクレイピングを実施していきます。
まずはpipでSeleniumをインストールしましょう。
$ pip install selenium次が今回のコードです。長いですが、一つずつ見ていきましょう。
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains #マウスオーバーするために必要
# アクセスするURL
URL = "https://myafu-python.com/"
# 各動作間の待ち時間(秒)
INTERVAL = 3
# 検索するidの一覧
ID_LIST = ['menu-item-680', 'menu-item-681', 'menu-item-682']
# ブラウザ起動
driver_path = "./chromedriver"
driver = webdriver.Chrome(executable_path=driver_path)
# windowサイズをmaxにする
driver.maximize_window()
time.sleep(INTERVAL)
# サイトを開く
driver.get(URL)
time.sleep(INTERVAL)
# IDに紐づくリストをクリックして画面遷移する
for ID in ID_LIST:
#マウスオーバーを使うための宣言
actions = ActionChains(driver)
#「文法」にマウスオーバー
target_text = "文法"
actions.move_to_element(driver.find_element_by_xpath("//*[text()='%s']" % target_text)).perform()
time.sleep(INTERVAL)
# idに紐づくリンクをクリックして次の画面を開く
driver.find_element_by_id(ID).click()
time.sleep(INTERVAL)
# 遷移先画面のクラス名がentry-card-titleの要素を全て取得(記事のタイトル)
titles = driver.find_elements_by_class_name('entry-card-title')
# 取得した記事のタイトルを出力する
for title in titles:
print(title.text + ":" + ID)
# 前の画面へ戻る
driver.back()
time.sleep(INTERVAL)
# ブラウザを閉じる
driver.close()[出力結果]
Herokuの特徴と基本的な使い方:menu-item-680
ライブラリ、モジュールとは?:menu-item-681
NumPyの基本:menu-item-681
pandasの基本:menu-item-681
matplotlibの基本:menu-item-681
スクレイピングで必須のライブラリ (urllib、requests、beautiful soup):menu-item-681
Pythonの特徴・基本の書き方:menu-item-682
型(数値や文字列など):menu-item-682
定数と変数:menu-item-682
条件分岐(if):menu-item-682
例外処理(try~except):menu-item-682
リスト(list)の使い方:menu-item-682
辞書(dict)型の使い方:menu-item-682
繰り返し処理(while文):menu-item-682
繰り返し処理(for):menu-item-682
関数の使い方:menu-item-682
タプル(tuple)の使い方:menu-item-682
文字コードの基本(エンコードやバイナリーなど):menu-item-682上のコードでやっていることは「文法タブの下にある3つのリンク先の記事タイトルの収集」です。
一つずつ見ていきましょう。まずはimportからです。
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChainstimeはChromeの立ち上げや画面遷移の時に、ちゃんと読み込んでから次の処理へ移るためのsleep処理を入れるために使います。
webdriverはSeleniumを動かすために必須です。またActionChainsはSeleniumを使ってマウスオーバー処理をするために使います。
次に設定です。
URL = "https://myafu-python.com/"
INTERVAL = 3
ID_LIST = ['menu-item-680', 'menu-item-681', 'menu-item-682']URLはアクセスするURL、INTERVALはtimeを使う時の待ち時間(秒数)です。
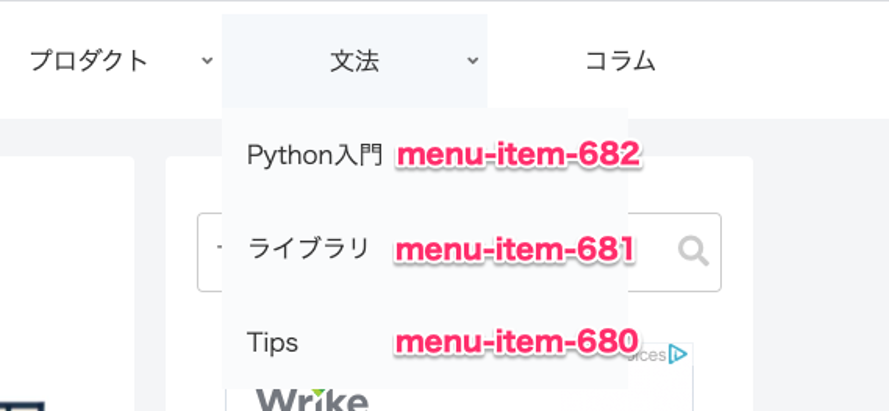
重要なのはID_LISTで、最初に開く画面の、文法タブ配下のリンクのidが入っています。
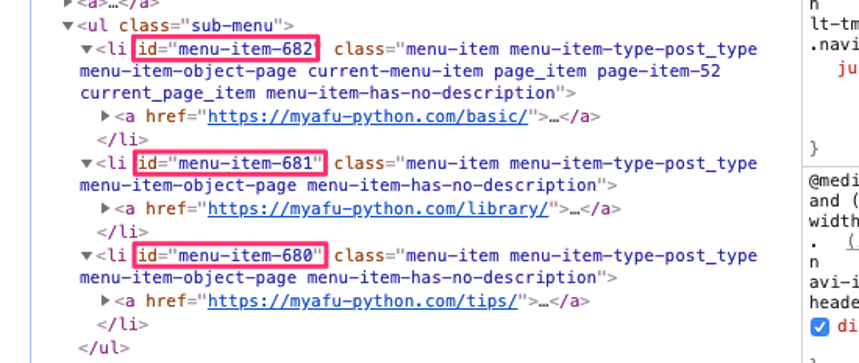
それぞれ [menu-item-682:Python入門][menu-item-681:ライブラリ] [menu-item-680:Tips] に紐づいています。
driver_path = "./chromedriver"
driver = webdriver.Chrome(executable_path=driver_path)driver_pathには先ほどダウンロードしたChromeDriverのパスを指定します。今回はソースコードと同じディレクトリに配置しています。
次にChromeDriverを使ってChromeを立ち上げます。
driver.maximize_window()
time.sleep(INTERVAL)ここではブラウザの最大化をしています。
また、ここでtime.sleepを呼び出しています。INTERVALに指定した秒数処理をストップし、ブラウザがちゃんと起動し終わるまで待ちます。
driver.get(URL)
time.sleep(INTERVAL)driver.getにURLを渡すことでサイトを開きます。サイトが開き終わるまでまた処理をストップさせます。
次にID_LIST分ループさせます。ループ内では次のような処理をしています。
actions = ActionChains(driver)
target_text = "文法"
actions.move_to_element(driver.find_element_by_xpath("//*[text()='%s']" % target_text)).perform()
time.sleep(INTERVAL)ここでは遷移先リンクをクリックするために、文法タブへのマウスオーバー処理を実行しています。
SeleniumではJavaScriptによって動的にページを変えながら操作できるので、このようなことが可能です。これはurllibやrequestsではできません。
driver.find_element_by_id(ID).click()
time.sleep(INTERVAL)driver.find_element_by_idに遷移先リンクのidを渡して要素を取得し、click()で画面遷移しています。
titles = driver.find_elements_by_class_name('entry-card-title')遷移先の記事のタイトルを、今度はfind_elements_by_class_nameにクラス名を渡して複数取得しています。
for title in titles:
print(title.text + ":" + ID)
driver.back()
time.sleep(INTERVAL)後は取得した記事タイトルを出力して、driver.back()で前の画面に戻ります。
前の画面に戻ったら次のIDに対応した画面を一つずつ開いていき、記事タイトルを取得していきます。
driver.close()全てのリンクを辿ってタイトルを収集し終えたらブラウザを閉じて、終了です。



