

セットは複数の値を「集合」として扱いときに便利な構文です。
集合は高校の数Iあたりで習ったやつです。2つの◯を重ねた「ベン図」という図を使って集合を表現した覚えがあると思います。
ここでは「セットって何?」「どうやって使うの?」「リストやタプルとの違いは」といった疑問に答えつつ、セットについて理解を深めていきましょう。
YouTubeも公開していますので、動画や音声で聞きたい方はぜひご覧ください。
集合とは
勉強した覚えのある方も多いかと思いますが、セットの使い方の前に集合について見ていきましょう。
集合はある複数の値を属性に応じてグループ分けする手法です。例えば「猫が好きな人」と「犬が好きな人」のように分けます。
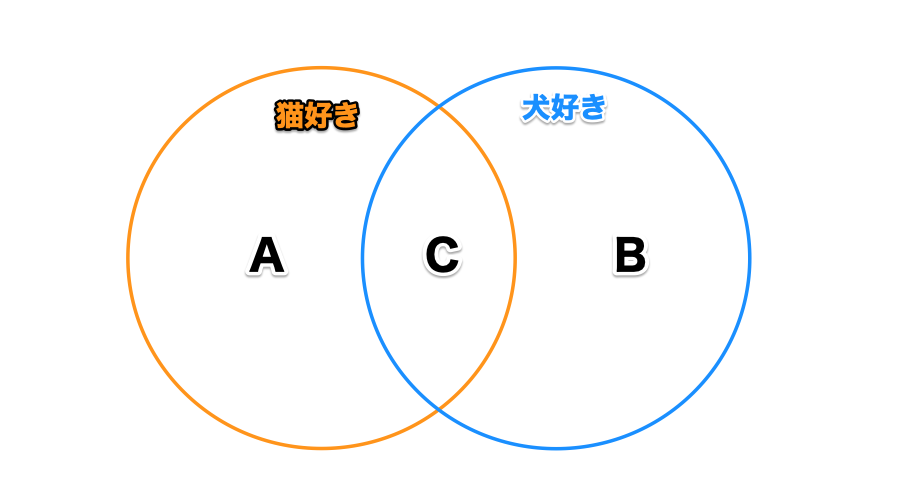
こうしてグループ分けすることを集合と呼びます。
集合は足し算、引き算、掛け算で表すことができます。それぞれの表現方法は以下の通りです。
- 猫か犬どちらか、または両方好き:A + B
- 猫だけ好き:A - B
- 猫も犬も両方好き(C):A * B
- 猫だけ好き、または犬だけ好き(C以外):(A + B) - (A * B)
最後だけ少し分かりにくいですが、これは「2つの集合の全体から、猫も犬も両方好きな人(Cの部分)を除く」計算式です。
Pythonではこういった集合の計算を「set」という構文を使って表現します。
セット(set)の初期化
ではここからセットを使って集合の計算をしてみましょう。
まずはセットの基本的な初期化方法からです。
{要素1, 要素2, 要素3, ...}構文自体は辞書に似ていますが、辞書はkey : valueだったの対して、セットはvalueだけカンマ区切りで指定する点が異なります。
実際にセットを初期化してみましょう。
A = {"sato", "suzuki", "tanaka"}
print(A)
print(type(A))[出力結果]
{'suzuki', 'sato', 'tanaka'}
<class 'set'>Aというセットを初期化しました。結果を見てわかる通り、ちゃんとsetとして作られています。
また、よく見ると初期化時の要素の順番と結果の要素の順番が異なっています。これは「セットは要素の順番を保証していないから」です。ここら辺はリストやタプルと異なる点なので注意が必要です。
また、セットはset()を使うことでも初期化できます。set()を使うことでリストやタプル、文字列をセットに変換できます。
list = ["sato", "suzuki", "tanaka"]
A = set(list)
print(A)[出力結果]
{'sato', 'tanaka', 'suzuki'}要素の追加・削除
次にセットの要素の追加と削除の方法を見ていきましょう。
要素の追加 - add()
セットに要素を追加するにはadd()を使います。
A = set() #空
A.add('sato')
A.add('suzuki')
print(A)[出力結果]
{'sato', 'suzuki'}また、セットでは「重複した要素を持てないので、同じ値を追加しても1つは無視されます」。リストにはインデックス番号で管理されているので値の重複は可能ですが、セットは値しかもっていないからです。
A = set()
A.add('sato')
A.add('sato') #同じ値
print(A)[出力結果]
{'sato'}要素の削除 - remove()
リストと同じく、要素を削除したい場合はremove()を使い、要素の値を指定して削除します。
また、指定した値が存在しない場合はKeyErrorになってしまいます。回避するためにremove()の前に指定する値がセット内に存在するか確認しましょう。
A = {"sato", "suzuki", "tanaka"}
if "suzuki" in A:
A.remove("suzuki")
print(A)セットを使った集合演算
ここからはセットを使って集合演算(足し算、引き算、掛け算)する方法を見ていきましょう。
ここでは冒頭で紹介した次の4つのパターンを、セットを使って表現します。
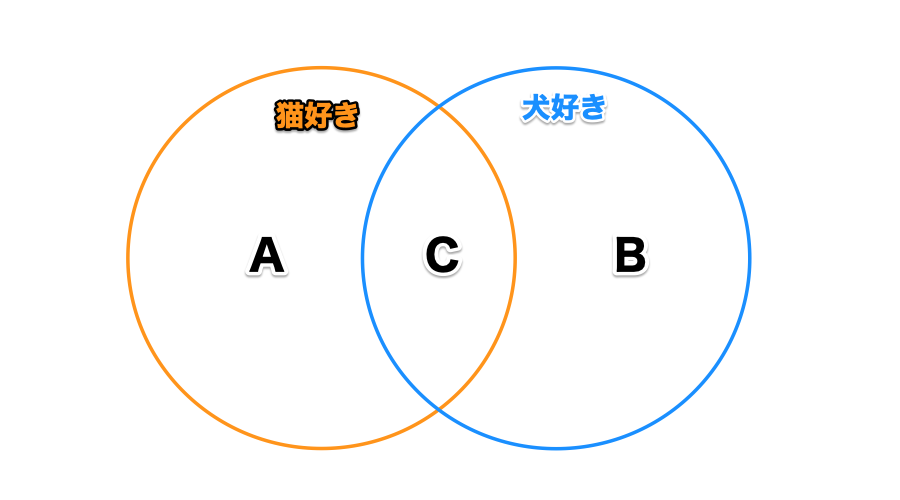
- 猫か犬どちらか、または両方好き:A + B
- 猫だけ好き:A - B
- 猫も犬も両方好き(C):A * B
- 猫だけ好き、または犬だけ好き(C以外):(A + B) - (A * B)
なおここからは基本的に次の2つの集合を用いて解説します。
A = {"sato", "suzuki", "tanaka"} #猫好き
B = {"sato", "ito", "kato"} #犬好き和集合 - A集合とB集合の要素を合わせる
まずは「A + B」の集合演算から見ていきましょう。
AとBの和集合は「|」記号を使います。
AorB = A | B
print(AorB)[出力結果]
{'sato', 'ito', 'tanaka', 'kato', 'suzuki'}「猫か犬どちらか、または両方好き」な集合を「|」記号で新たに作成しました。
佐藤さんは猫も犬も好きなので両方の集合に属していますが、集合の重複が許可されていないので、1つのみ集合内に入っています。
差集合 - A集合からB集合の部分を取り除く
次に「A - B」の集合演算を見ていきましょう。
差集合は「-」記号を使います。
AminusB = A - B
BminusA = B - A
print(AminusB)
print(BminusA)[出力結果]
{'tanaka', 'suzuki'}
{'kato', 'ito'}「A - B」は「猫だけ好きな人」、「B - A」は「犬だけ好きな人」を表現しています。
新たに作成されたどちらの集合も「猫も犬も好きな佐藤さん」が除かれているのが分かります。
積集合 - A集合とB集合の共通部分を抽出する
次に「A * B」の集合演算を見ていきましょう。
積集合は「&」記号を使います。
AandB = A & B
print(AandB)[出力結果]
{'sato'}「猫も犬も好きな人」の集合を「&」を使って作成しました。先ほどの画像で言うところのCの箇所ですね。
排他的論理和 - どちらかの集合にしか所属しない要素を抽出する
最後に排他的論理和について見ていきましょう。
排他的論理和とは「2つの集合の内、片方だけ所属する要素」を全て抽出するものです。
「猫だけ好き、または犬だけ好き(C以外)」が該当します。
排他的論理和は(A + B) - (A * B)で表せますが、Pythonでは「^」記号を使えば簡単に演算できます。
Aexclusive_orB = A ^ B
print(Aexclusive_orB)[出力結果]
{'tanaka', 'kato', 'ito', 'suzuki'}先ほどの画像で言うところのCに属する佐藤さんだけが除かれました。
セットの比較方法
ここでは2つのセットの比較方法を解説します。
要素が完全に一致している場合や、共通要素が1つでも存在するかどうかを調べる方法があります。
セットの完全一致
セットの要素が完全に一致しているかどうかを確認するには「==」を使います。
A = {1, 2, 3}
B = {3, 2, 1}
C = {1, 2, 4}
print(A == B)
print(C == B)[出力結果]
True
FalseAとBはお互い1と2と3が入っているので完全に一致しています。要素を挿入する順番は違いますが、セットでは要素の順番は保証されていないのでTrueになります。
一方Cには4が入っており、要素が完全一致していないのでFalseになります。
セットの部分一致
セットの要素が1つでも一致しているかどうかを確認するにはisdisjoint()を使います。
isdisjoint()は「共通要素がない場合True、ある場合はFalse」を返すメソッドです。
A = {1, 2, 3}
B = {4, 5, 6}
C = {6, 7, 8}
print(A.isdisjoint(B))
print(C.isdisjoint(B))[出力結果]
True
FalseAとBは一致する要素一つもないのでTrueになっています。
一方CとBは「6」の要素が一致しているのでFalseになりました。
セットを使ってリストの重複を除去する
最後にセットの応用的な使い方をご紹介します。
リストの重複している値を除去し、全ての要素をユニークにしたい場合はset()を使って一度セットに変換し、リストに再度変換し直すという方法があります。
セットを使うと、本来次のように記述する必要があるところを
ununique_list = [3, 1, 2, 3, 2, 1, 3, 3, 3, 2, 1]
unique_list = []
for i in ununique_list:
if not i in unique_list:
unique_list.append(i)以下のように、これだけスッキリ書けます。
ununique_list = [3, 1, 2, 3, 2, 1, 3, 3, 3, 2, 1]
unique_list = list(set(ununique_list))ただし、セットを通す場合は再作成されたリストの要素の順番が保証されません。
要素の順番が重要な場合はsort()などのメソッドを使いましょう。



