

テキストマイニングとは?
テキストマイニングとは、テキストをプログラムに分析してもらい、文章の特徴を図や色などで表現することを指します。
SNSで注目されている単語やGoogle検索トレンドなども瞬時で分析でき、データサイエンティストやマーケターなども活用できます。
今回行うテキストマイニングで特に重要な処理が「形態素解析」と呼ばれるもので、繋がっている文章の中から単語を抜き出して意味を割り出す分析方法です。
例えば、私たち人間が「このサイトは非プログラマーが日常業務で使えるシンプルなPythonを紹介するメディアです。」
をという文章を読む時には
「この/サイト/は/非/プログラマー/が/日常/業務/で/使える/シンプル/な/Python/を/紹介/す/る/メディア/です。/」
と区切ることができます。しかし(英語は単語ごとにスペースを開けるのでプログラムで処理をしなくても問題はありませんが)、言葉が繋がっている日本語は文章や言葉を最小単位に分解しないと文字の解析ができません。
形態素解析は自然言語処理によって単語に分割しています。自然言語処理は私たちが日常的に無意識に分割している作業をコンピュータに処理させる技術です。
テキストマイニングをするメリット
仕組みの話をしても使い道がピンと来ないかも知れませんが、テキストマイニングを活用すると業務でも色々なことに使用できます。
- 売れている作家がどのような文字をたくさん使っているか分かる
- SNSのデータも分析できるので、マーケティングに活用できる
- 市場、世間の声が分かる
- アンケート等では分からない、潜在的なニーズを探ることができる
など…
自分の好きな作家やブロガーが実際にどのような言葉を使用しているか瞬時に分析できるので、その人の口癖や性格なども可視化できます。
読み取った文章内にある単語を利用するので、SNSなどからデータを持ってきた場合はリアルタイムで世の中の声を抽出できます。Google検索をする時は文字を使い、動画や写真を探す時も文字は利用されるので、テキストデータを解析できるとより分析能力が高まります。
災害や経済危機などで人々がどのような事を感じてSNSに投稿しているかも可視化できます。
人々の行動パターンからニーズ、口コミなど様々な方法で活用できるのがメリットです。顕在化していないニーズを可視化できるのもテキストマイニングの大きなメリットです。
数万文字のテキストマイニングを低スペックのパソコンで実行しても比較的早く処理が終了するので、テキストデータを活用したい方にはおすすめの機能です。
ライブラリWordCloudを使ったテキストマイニングと視覚化
今回は「WordCloud」と「MeCab」の二つのライブラリを使用します。
WordCloudは取得した文章の中で特に多く利用されるほど文字を大きく画像に表示させることができるライブラリです。大きさだけではなく色もつけてくれるので、より見やすいデザインで作成ができます。
MeCabは形態素解析エンジンで、文章の自然言語処理を行ってくれるライブラリです。
この2つをインストールしましょう。
pip install wordcloud
pip install mecab-python3
Windowsの場合は直接ダウンロードしてください。
ダウンロードして実行した後は、システム環境変数の「Path」に「C:\Program Files\MeCab\bin」のようにMeCabのbinまでのパスを追加編集してください。
システム環境変数と検索
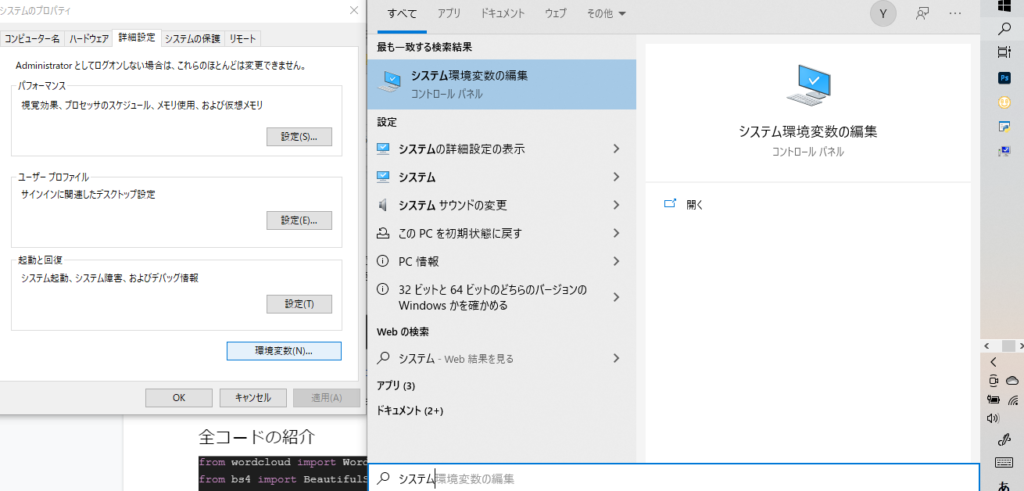
システム環境変数の「Path」をクリックして、編集をクリック
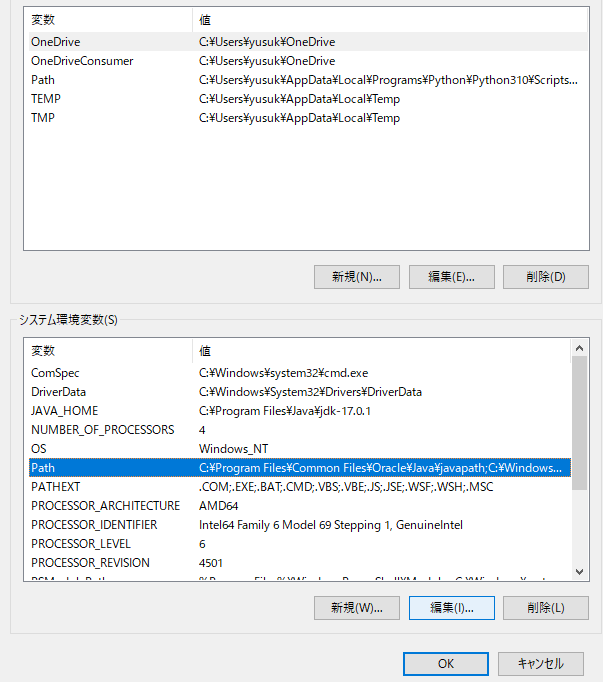
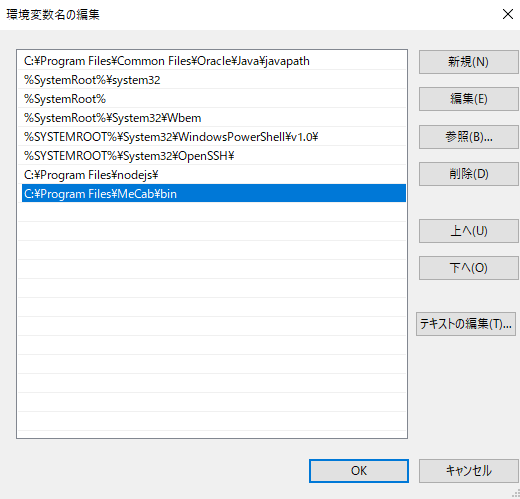
新規をクリックして、MeCabがインストールされているパスを設定しましょう。
今回はこのライブラリを使って、青空文庫で公開されている夏目漱石の名作「こころ」をテキストマイニングし、使用されている単語を分析してみたいと思います!
全コードの紹介
from wordcloud import WordCloud
from bs4 import BeautifulSoup
import requests
import MeCab
#文章を取得
response = requests.get('https://www.aozora.gr.jp/cards/000148/files/773_14560.html')
soup = BeautifulSoup(response.content, 'lxml')
text = soup.find('div', class_='main_text')
text = text.get_text()
#MeCabの準備
tagger = MeCab.Tagger()
tagger.parse('')
text = tagger.parseToNode(text)
#名詞だけ取り出す
text_list = []
while text:
word_type = text.feature.split(',')[0]
if word_type == '名詞':
text_list.append(text.surface)
text = text.next
#リストを文字列に変換
image_text = ' '.join(text_list)
#除外する単語
stop_text = ["それ", "の", "あと", "たち", "そこ", "うち"]
#wordcloudの設定
wordcloud = WordCloud(background_color="white",
font_path=r"C:\Windows\Fonts\メイリオ\meiryo.ttc",
collocations = False,
stopwords = stop_text,
width=3840,height=2160).generate(image_text)
#画像生成
wordcloud.to_file(r"C:\保存先のパス\aozora.jpeg")
上記のソースコードを実行すると、夏目漱石の「こころ」で多く利用されている言葉を可視化できます。実際に実行したものはコード解説の後に紹介します。
各コードの解説
それでは各コードについて解説していきましょう。
ライブラリのインポート
from wordcloud import WordCloud
from bs4 import BeautifulSoup
import requests
import MeCab
先ほど紹介した「WordCloud」「MeCab」に合わせ、Webサイトから抽出してくるのでスクレイピングのライブラリである「BeautifulSoup」とURLを開く為の「requests」を使います。
スクレイピングの実行
#文章を取得
response = requests.get('https://www.aozora.gr.jp/cards/000148/files/773_14560.html')
soup = BeautifulSoup(response.content, 'lxml')
text = soup.find('div', class_='main_text')
text = text.get_text()
7行目でスクレイピングするサイトのURLを設定し、8行目でスクレイピングします。
夏目漱石「こころ」のWebサイトはmain_textクラスの中に収まっているので、main_textを選択し、10行目はHTMLタグを除外する為、get_text()を利用します。
最終的に取得した物はtextの中に入れます。
形態素解析
#MeCabの準備
tagger = MeCab.Tagger()
tagger.parse('')
text = tagger.parseToNode(text)
13行目で形態素解析をするための辞書を指定します。
14行目で文字列やテキストファイルを形態素解析しています。
15行目でMecab内で生成される文頭の形態素のインスタンスを返します。
出力させる文字を選ぶ
#名詞だけ取り出す
text_list = []
while text:
word_type = text.feature.split(',')[0]
if word_type == '名詞':
text_list.append(text.surface)
text = text.next
18行目でリストを宣言し、while文でtextに値が入っている分だけ処理を繰り返します。
Mecabでは名詞や品詞を取得できるので、今回は名詞を取得するために[0]を設定します。この数値を1に変えると品詞を取得できます。
次の行で名詞だけを取得するように条件分岐させます。
そしてappendを使用して名詞をtext_listの中に繰り返し入れていきます。
表示させたくない文字を選ぶ
#リストを文字列に変換
image_text = ' '.join(text_list)
#除外する単語
stop_text = ["それ", "の", "あと", "たち", "そこ", "うち"]
26行目でtext_listに入れた名詞をimage_textに入れますが、一つの文章にする際にjoin句でスペースを入れ、名詞の前後に空白を入れます。これで画像を生成する際に単語をしっかりと区別できます。
場合にもよりますが、接続詞や不適切な言葉を使用したくない場合はstop_textに表示させたくないキーワードを入れます。
テキストマイニングした画像を生成
#wordcloudの設定
wordcloud = WordCloud(background_color="white",
font_path=r"C:\Windows\Fonts\メイリオ\meiryo.ttc",
collocations = False,
stopwords = stop_text,
width=3840,height=2160).generate(image_text)
#画像生成
wordcloud.to_file(r"C:\保存先のパス\aozora.jpeg")
32行目でwordcloudを設定していきます。
background_colorは画像の背景色を指定します。
font_pathでフォントを指定しない場合、画像生成した時に日本語が文字化けてしまいます。
collocationsはデフォルトだとTrueになっていますが、Trueだと単語が重複してしまう可能性があります。例えば「Python」と「Python やり方」があった場合「Python やり方」のPythonの部分が重複してより多くの情報を抽出できません。Falseにすると「Python」と「やり方」が別の単語と認識され、「Python」が重複しません。別の単語として認識されるには「Pythonやり方」のように繋がっているケースです。
stopwordsでは画像に表示させない設定をします。
widthとheightで画像の大きさを指定します。
最後にgenerateでimage_textにセットした単語たちをセットします。
他にも「min_word_length=2,」を入れると少なくても2文字以上の文字が表示されます。
39行目ではwordcloudに設定したwordcloudオブジェクトをto_fileで保存します。
出力結果とその内訳分析
一枚目はMeCabを使わないで生成した結果です。

青空文庫で掲載されている「こころ」は、所々漢字にフリガナが振られています。こちらがしっかり区切られてないため、この漢字のフリガナしか単語として認識されませんでした。
2枚目は除外する単語を設定しなかった場合です。

1枚目よりかは若干本文の単語が抽出できていますが、接続詞のせいで単語があまり表示されませんね。
3枚目は接続詞を除外して生成した結果です。

接続詞でもフリガナでもなく、本文に多く利用されている単語が抽出されました。単語が多く抽出されたことにより漢字も多く抽出されているのが分かります。
夏目漱石の「こころ」では特に「私」「先生」「奥さん」などが多く利用されている事が分かります。他にも「自分」「お嬢さん」など、人間関係をテーマにした小説だけに人称や呼び名の単語が多いことが分かりますね。
今回は権利の関係上青空文庫を対象にしましたが、例えば雑記ブログを運営している方が全記事丸ごとマイニングして頻出単語を分析したりすると、自分がどんなテーマや表現を使っているのか可視化ができて面白かったりします。その他SNS、スピーチ、データベースなど色々な媒体で使うことができますので、是非試してみてください。


