

Pythonで内部・外部リンクのリストやリンクエラーの一覧を出力できれば、SEOやUXの改善に役立ちます。
ここではPythonを使って、Excelに自サイトの内部リンク・外部リンク・リンクエラーのリストを出力するスクリプトをご紹介します。
サーチコンソールの問題
Googleが提供しているサーチコンソールを使うことでもサイトの内部/外部リンクを分析することは可能です。
しかし、サーチコンソールには以下の問題があります。
- 内部/外部リンクが0のページが表示されない。
- リンクエラーは表示されないので、手動でチェックする必要がある
- 内部/外部リンクはデータとして存在しない
特にリンクエラーの手動チェックはページ数が増えてくると非常に面倒になってくるので、できれば自動化したいところです。
なので、ここで紹介するスクリプトでは
- 内部/外部リンクが0のページも出力する
- リンクエラーを起こしているページの場所と、エラー数、エラーの種類を出力する
これらの課題を解決し、Excelファイルに出力して一覧化して分析できるようにします。
下記で紹介するスクリプトを実行することで、次のデータ一覧を取得できます。
- ページURL
- 内部リンク数
- 外部リンク数
- 外部リンク一覧
- リンクエラー数
- 内部リンクエラー
- 外部リンクエラー
使用するライブラリ
今ページのスクリプトで使用されているライブラリの一覧です。
requests / Beautiful soup
requestsは主にPythonからHTTPリクエストを送信し、結果を取得するライブラリです。
またBeautiful soupはhtmlをパース(解析)し、必要な情報をプログラム内で扱いやすくするためのライブラリです。

openpyxl
openpyxlはPythonからExcelファイルを作成・操作するためのライブラリです。

スクリプトの紹介
こちらが紹介するスクリプトです。
import requests
from bs4 import BeautifulSoup
import openpyxl
import re
import time
#ワークブックとシートの作成
workbook = openpyxl.Workbook()
sheet = workbook.active
#ヘッダを書く
sheet['A1'].value = 'ページURL'
sheet['B1'].value = '内部リンク数'
sheet['C1'].value = '外部リンク数'
sheet['D1'].value = '外部リンク一覧'
sheet['E1'].value = 'リンクエラー数'
sheet['F1'].value = '内部リンクエラー' # リンクエラーを起こしている場合はリンク場所とエラー内容を出力する
sheet['G1'].value = '外部リンクエラー'
# トップページ
root_url = 'https://myafu-python.com'
# ページURLの一覧
page_urls = set()
# 引数のsrc_urlのページにあるURLから別のページのURLを取得する
def get_link(src_url):
global pages
response = requests.get(src_url)
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all("a", href=re.compile(f"^{root_url}")):
if 'href' in link.attrs:
page_url = link.attrs['href']
if page_url not in page_urls:
page_urls.add(page_url)
get_link(page_url)
# サイト内のページURLの一覧を作成する
def create_page_urls():
get_link(root_url)
print("内部ページURL一覧取得中...")
create_page_urls()
print("内部ページURL一覧取得完了")
# テスト用
# page_urls = {'https://myafu-python.com/generator/', 'https://myafu-python.com/jinja2/', 'https://myafu-python.com/line-basic/'}
print("各ページの内部・外部リンク・リンクエラーを取得中...")
#各ページのリンクを取得し、内部リンクと外部リンクに分けた後Excelに書き出し
for i, page_url in enumerate(page_urls, start=2):
print(f"処理中:{page_url}")
sheet[f"D{i}"].value = ""
sheet[f"F{i}"].value = ""
sheet[f"G{i}"].value = ""
# ページURL
sheet[f"A{i}"].value = page_url
response = requests.get(page_url)
soup = BeautifulSoup(response.text, 'html.parser')
# 内部・外部リンクの一覧を作成
inner_urls = set()
outer_urls = set()
for link in soup.find_all("a", href=re.compile(f"^http")):
if 'href' in link.attrs:
link_page_url = link.attrs['href']
# Trueなら内部リンク、Falseなら外部リンク
if root_url in link_page_url:
inner_urls.add(link_page_url)
else:
outer_urls.add(link_page_url)
sheet[f"D{i}"].value = sheet[f"D{i}"].value + "\n" + link_page_url
# 内部リンク数
sheet[f"B{i}"].value = len(inner_urls)
# 外部リンク数
sheet[f"C{i}"].value = len(outer_urls)
#リンクエラーの書き出し
link_error_count = 0
for inner_url in inner_urls:
try:
response = requests.get(inner_url)
except:
# 例外発生時はリンクエラー扱いにする
link_error_count = link_error_count + 1
sheet[f"F{i}"].value = sheet[f"F{i}"].value + f"\n999 {inner_url}"
continue
if (response.status_code in [403, 404]):
# 403、404はリンクエラー
link_error_count = link_error_count + 1
sheet[f"F{i}"].value = sheet[f"F{i}"].value + f"\n{response.status_code} {inner_url}"
for outer_url in outer_urls:
try:
response = requests.get(outer_url)
except:
link_error_count = link_error_count + 1
sheet[f"G{i}"].value = sheet[f"G{i}"].value + f"\n999 {outer_url}"
continue
if (response.status_code in [403, 404]):
# 403、404はリンクエラー
link_error_count = link_error_count + 1
sheet[f"G{i}"].value = sheet[f"G{i}"].value + f"\n{response.status_code} {outer_url}"
# リンクエラー数
sheet[f"E{i}"].value = link_error_count
# 同じサーバに何度もリクエストするとエラーが返されてしまうので、5秒間待つ
time.sleep(5)
print("各ページの内部・外部リンク・リンクエラー取得完了")
# 作成したExcelファイルを保存
print("Excelファイルに書き出し")
workbook.save("result.xlsx")
ここからはソースコードの主要な箇所を解説していきます。
8行目のopenpyxl.Workbook()でExcelのワークブックを作成し、9行目のworkbook.activeでExcelのシートを作成し、sheet変数に格納しています。
内部・外部リンクの分析用リストはこのシートに書き出していきます。
11〜17行目はヘッダ項目を書き出しています。
20行目のroot_urlに分析したいサイトのトップページのURLを格納します。
22行目には41行目のcreate_page_urls()を実行することでページURLの一覧がリスト形式で格納されます。
25〜34行目のget_link()は再帰処理しながら内部リンクを全て取得するための関数です。
29行目のfind_allは1つ目の引数のタグを2つ目の引数でフィルタリングした結果を返しています。href=re.compile(f"^{root_url}")は「文字列先頭がroot_url」なhref属性という意味になるので、内部ページのみ抽出されます。
49行目からの処理は取得したページ一覧のURLをループさせ、必要な情報を取得してExcelに書き込んでいます。
62〜72行目は各ページごとの内部・外部リンクのリストを作成し、inner_urlsとouter_urlsに格納しています。
81〜103行目は取得した内部・外部リンクごとにリンクエラーURLとエラーコードをrequests.get()を使って抽出し、Excelに書き出しています。
例外が発生した場合はエラーコードを999にしています。
全ての項目を書き出したら次のページURLを処理し、全て終わったらworkbook.save()でExcelファイルを保存しています。
スクリプトの活用方法
実際にみゃふのサイトで出力すると以下のようなExcelファイルが出力されます。
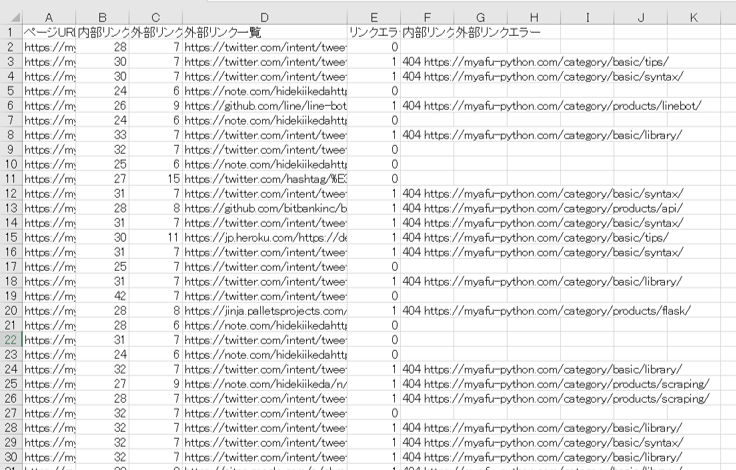
内部リンク・外部リンクがが無い記事がある場合は関連記事や別ページへのリンクを貼れないかを再度確認したり、リンクエラーが発生しているページはリンクを修正することでUXの改善を計れます。
こういった活用はGoogleサーチコンソールではできません。是非当スクリプトをご活用下さい。



