

プログラムの概要
Kaggleのタイタニック号の生存者を予測する方法で、データ分析の基本を解説します。
Pythonでデータ分析をやってみる場合、仕事などで分析するデータを持っている場合以外は、データを持っていないと思いますので、 Kaggleを利用するのがおススメです。
Kaggleのデータ分析は、突き詰めれば突き詰めるほど、難解なモデルを作っていくことができます。ただ、今回は、まず体験してみたいという初心者の方向けに、解説しますので、 可能な限り簡単な実装方法にします。
Kaggle(カグル)とは?
Kaggleは世界でもっとも有名な機械学習のコンペティションです。
Kaggleには様々なテーマが設定されており、そのテーマに沿って与えられたデータを最適化していくコンペになります。
タイタニック号の生存者を予測するコンペは、Kaggleの中でも有名なコンペの一つです。
タイタニックでは、約900名分の乗客のデータが与えられますが、それぞれの乗客の属性(年齢、性別など)が入っています。一部欠損値がありますので、それらを補完しながら、データが与えられていない乗客に対して、生存しているか、生存していないかを判別するモデルを作るというものです。
データ分析の流れ
以下のような流れでデータ分析を進めていきます。
1、Kaggleからデータをダウンロード
2、ダウンロードしたデータをもとに、最適化したモデルを作成
3、2で作成したモデルをもとに、別のデータに対して、モデルを適用することで、生存生存しているか、を予測。
4、Kaggleにアップロードして生存率を判定
データ分析の準備
Kaggleからデータをダウンロード
まず、データ分析を行う元となるデータを以下のサイトから2つダウンロードします。
test.csv
train.csv
データの確認
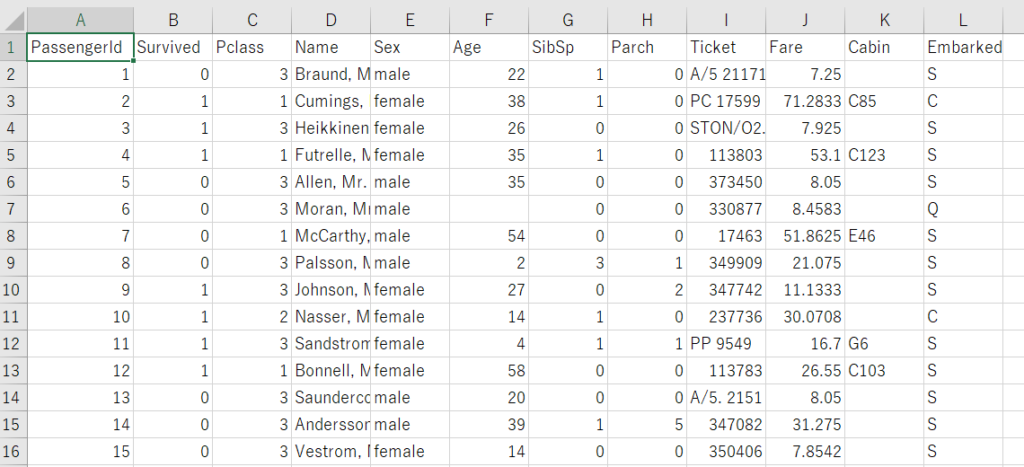
上記のようにtrain.csvには、PassengerIDからEmbarkedまで、一人一人の乗客に対して13個の属性が入っていることがわかります。なお、test.csvはtrain.csvでモデルを作成した後に、生存しているかどうかを予測するために使うため、Survived列が入っていません。
ライブラリーのインポート
CSVファイルを開いて確認しましたが、具体的にどのようなデータが入っているかもう少し詳しく、確認してみます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')まず、今回使うライブラリーをインポートします。
NumPy、Pundas、matplotlibなど、データ分析には必須のライブラリーです。
これらがわからない場合は、NumPyやPandasの基本を勉強してからこの記事を見ると理解しやすいでしょう。

5行目、6行目では、CSVを読み込み変数df、df_testにそれぞれ代入しています。
Google Colaboratoryを利用する場合は、GoogleドライブにCSVをアップして、ドライブ上で直接ファイルを操作すると便利です。
from google.colab import drive
drive.mount('/content/drive')
df = pd.read_csv('/content/drive/My Drive/train.csv')
df_test = pd.read_csv('/content/drive/My Drive/test.csv') 1行目、2行目で、Googleドライブのファイルを操作できるコードを書きます。
すると、Google認証が開きますので、認証コードを入力すると使えるようになります。
読み込む際も、3行目、4行目のようにファイルを置くと読み込めますので参考にしてください。
まずは、データフレームを出力してみましょう。
print(df.head()) PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns]このようにデータフレームで読み込まれたのがわかります。
次にどのようなデータが入っているかを確認してみます。
df.columnsIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')※参考までに各変数の内容は以下になります。
| 変数 | 内容 | 備考 |
|---|---|---|
| Survived | 生存したかどうか | 0 = No, 1 = Yes |
| Pclass | チケットのクラス | 1 = 1st, 2 = 2nd, 3 = 3rd |
| Name | 名前 | |
| Sex | 性別 | |
| Age | 年齢 | |
| SibSp | 同乗していた兄弟や配偶者の数 | |
| Parch | 同乗していた親や子供の数 | |
| Ticket | チケット番号 | |
| Fare | チケット料金 | |
| Cabin | キャビン番号 | |
| embarked | 乗船した港 | C = Cherbourg, Q = Queenstown, S = Southampton |
続いて、統計量を表示させてみます。
df.describe()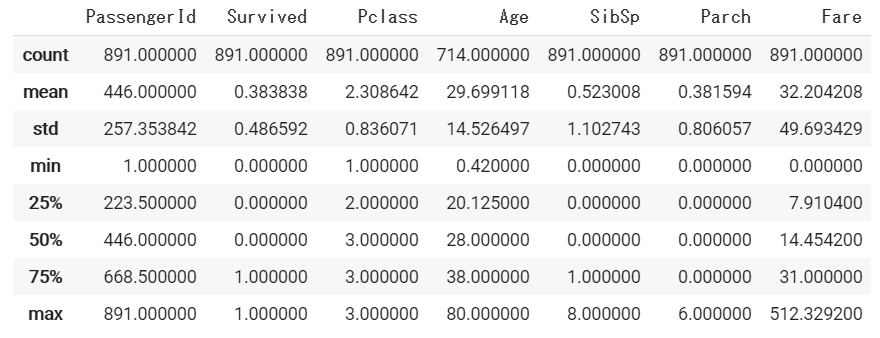
df.hist(figsize = (12,12))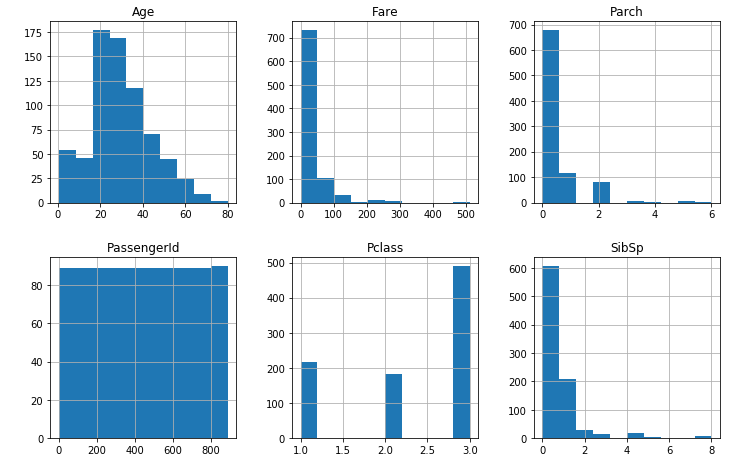
このように、どのようなデータが入っているか確認して、どのようにデータを加工していくか、最適化していくかを考えます。
データの前処理
ここから実際にデータを加工していきます。先程データを見ていただいてお気づきの方がいるかもしれませんが、データが一部入っていなかったり、名前や性別などそのままでは、学習ができないできない状態になっています。
そのため、これらを加工して、学習しやすいデータに加工する作業を行います。
そのまま学習できないことはありませんが、データを適切に加工した後の方が、最適な学習がされるため、基本的には、データを加工してから学習します。データサイエンス(データ分析)では、データを学習させるよりも、この前処理に多くの時間を費やすことが珍しくありません。
欠損値の確認
まずはじめに、どれぐらい欠損値(値が入っていない)が入っているか確認します。
df.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64Age、Cabin、Embarkedで欠損値があることがわかりました。
isnull()はPandasで欠損値が含まれているかをカウントしてくれるメソッドです。これらをsumで合計すると欠損値の数がわかります。
df_test.isnull().sum()PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64テストデータは、Age、Fare、Cabinが欠損していることがわかりました。
このあと、これらのデータを加工していきます。
Age(年齢)とFare(チケット料金)に値を追加
まず、上記で確認したAgeとFareの欠損している箇所に値を追加します。
df['Age'].fillna(df['Age'].mean(), inplace=True)
df_test['Age'].fillna(df_test['Age'].mean(), inplace=True)
# df['Fare'].fillna(df['Fare'].mean(), inplace=True)
df_test['Fare'].fillna(df_test['Fare'].mean(), inplace=True)欠損値を他の値に置換するメソッドとしてfillna()を使います。
今回は簡単に穴埋めをしたいので、全体の平均値を代入することとして、mean()で代入します。
dfおよびdf_testの両方の欠損値に代入します。
dfはFareが欠損していないので不要ですが、基本的にdf_testと同じ処理を書いていくこととします。
なお、デフォルトで元のオブジェクトは変更されないので、引数にinplace=True を指定して、元のオブジェクト自体が変更されるようにすることを忘れないようにしましょう。
今回、平均値で置換しましたが、中央値で置換することや、他の値と比較して、この値に機械学習を用いて置換する方法など、置換方法は多岐にわたります。
この補完によって、分析結果にかなり差が出るので、保管は非常に重要です。今回は簡単な方法で置換しましたが、いろいろな置換方法を試してみると良いでしょう。
df.isnull().sum() PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64df_test.isnull().sum()PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64isnull().sum()で確認すると、上記のようにdfとdf_testともにAgeとFareの欠損値がなくなりました。
カテゴリカルデータを置き換える
データの型には、大きく分けると数値データとカテゴリカルデータがあります。他にも日付・時間データなどがあったり、連続値データ/離散値データの区別などがあります。
数値データは文字通り数値が格納されたデータであり、カテゴリカルデータは主に文字列によってその分類が示されたデータです。ただしデータが数値であっても、その値の大小や順序が意味を持たない場合にはカテゴリカルデータとして扱う必要がある点には注意が必要です。
上記の観点では今回のデータは以下のように分類されます。
- 数値データ:Pclass、Age、SibSp、Parch、Fare
- カテゴリカルデータ:Name、Sex、Ticket、Cabin、Embarked
ここからは、カテゴリカルデータを変換していきます。
まず、Sex(性別)です。Sexは、値がmale、femaleとなっているので、これをmale=0、female = 1と変換することで、数値データに変換され、分析データとして扱いやすくなります。
df.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True)
df_test.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True)replaceをつかって、maleとfemaleを置き換えました。
続いてName、Ticket、Cabin、Embarkedです。
category_list = ['Name', 'Cabin', 'Ticket','Embarked']
df.drop(category_list, axis=1, inplace=True)
df_test.drop(category_list, axis=1, inplace=True)本来であれば、Sexと同様に数値に変換することで、学習結果がより最適化されますが、今回は簡単な方法にしたいので、drop()メソッドで、すべて削除してしまいます。
これで、欠損値およびカテゴリカルデータの置換ができました。
機械学習の実装
決定木で学習
ここからいよいよ、加工データを学習させてモデル化します。
今回は、比較的理解しやすい決定木という機械学習の手法を使います。
決定木については、以下のサイトがわかりやすいのでわからない方は参考にしてみてください。

from sklearn.tree import DecisionTreeClassifier
X = df[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare']].values
Y = df['Survived'].values
model = DecisionTreeClassifier(max_depth=3)
result = model.fit(X, Y)
model.score(X, Y)まず、決定木のライブラリーをインポートします。
次に値をX(説明変数)とY(目的変数)に分けます。
・説明変数:モデルの学習に使用する変数、今回の問題ではPassengerId, Survived以外の変数
・目的変数:予測対象の変数, 今回の問題ではSurvived
最後に、valuesをつけて、numpy.ndarray型に変換していますが、機械学習モデルの実装によってはこの型のデータしか受け付けないため、このようにしています。
5行目では、決定木の枝わけの数を引数に入れます。
6行目のfitで学習させて、その結果を変数resultに代入します。
8行目のsocreで正解率がわかります。前処理や機械学習の手法次第で、このスコアが変わってきます。
0.8271604938271605test.csvで予測する
test.csvを使い、先程学習したモデルがどの程度未知のデータに対して、予測できるかを実装していきます。
X_test = df_test.iloc[:, 1:].values
predict = model.predict(X_test)
predictilocを使い、test.csvデータの一列目(PassengerID)を削除します。
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])上記のように、生存結果が0または1で返ってきました。
Kaggleでは、このtest.csvに学習モデルを適用した結果を、提出します。
Kaggleに提出データに加工
Kaggleに提出するためのデータに加工します。
submit_csv = pd.concat([df_test['PassengerId'], pd.Series(predict)], axis=1)
submit_csv.columns = ['PassengerId', 'Survived']
submit_csv.to_csv('/content/drive/My Drive/submition.csv', index=False)1行目で、concatを使い、PassengerIDと予測した結果を結合するデータを作り、変数submit_csvに代入します。
2行目では、PassengerIDとSurvivedというカラム名を付けます。
最後に、CSVファイルとして書き出して、終了です。
これをKaggleにアップロードするとスコアと順位が表示されます。
コードのまとめ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
df = pd.read_csv('/content/drive/My Drive/train.csv')
df_test = pd.read_csv('/content/drive/My Drive/test.csv')
df['Age'].fillna(df['Age'].mean(), inplace=True)
df_test['Age'].fillna(df_test['Age'].mean(), inplace=True)
df_test['Fare'].fillna(df_test['Fare'].mean(), inplace=True)
df.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True)
df_test.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True)
category_list = ['Name', 'Cabin', 'Ticket','Embarked']
df.drop(category_list, axis=1, inplace=True)
df_test.drop(category_list, axis=1, inplace=True)
X = df[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare']].values
Y = df['Survived'].values
model = DecisionTreeClassifier(max_depth=3)
result = model.fit(X, Y)
X_test = df_test.iloc[:, 1:].values
predict = model.predict(X_test)
submit_csv = pd.concat([df_test['PassengerId'], pd.Series(predict)], axis=1)
submit_csv.columns = ['PassengerId', 'Survived']
submit_csv.to_csv('/content/drive/My Drive/submition.csv', index=False)以上がKaggleを利用したデータ分析です。今回は簡単にできるようにデータを削除したり、平均値で置き換えたりしましたが、このあたりの前処理をどのようにするかが、データ分析の重要な部分です。
今回の内容を参考に、Web上には様々な最適化の手法がありますので、ぜひ探してみてください。


