

フォルダをいくつか作る程度であれば手で作った方が早いですが、何十個も作らないといけない時はさすがに大変ですよね。
なので、ここではPythonを使って空のフォルダをcsvから作成する方法をご紹介します。
単純に作成する以外にも、深い階層のフォルダも作成できるプログラムも記載・解説していきます。
単階層のフォルダ一括作成
まずは一番シンプルに、単階層のフォルダ一括作成を見ていきましょう。 ここでは次のcsvを使います。
[folder_name1.csv]
プライベード
仕事
その他
import os
import csv
with open('folder_name1.csv') as f:
reader = csv.reader(f)
for row in reader:
if not os.path.exists(row[0]):
os.mkdir(f"./folder/{row[0]}")
[出力結果]
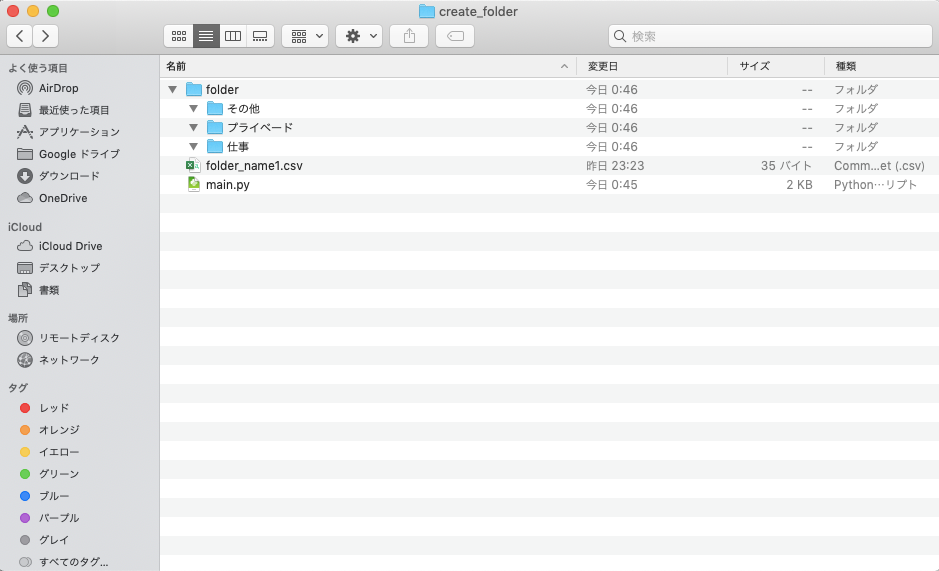
csvモジュールと繰り返し処理で読み込んだfolder_name1.csvを一行ずつ処理し、フォルダが存在しないことを確認したらos.mkdirでfolderフォルダ直下に1つずつフォルダを作成しています。
csv.reader()を使って1行ずつ処理する場合は、csvファイルの1列目からインデックス番号が割り当てられるので、フォルダ名をrow[0]で引っ張ってきています。
複階層のフォルダ一括作成
次に複階層を意識したフォルダ一括作成の方法を見ていきましょう。
使うcsvはこちらです。
[folder_name2.csv]
1,プライベード
1-1,写真
1-2,動画
2,仕事
2-1,本業
2-1-1,開発
2-1-2,社内研修
2-2,副業
2-2-1,ソフトウェア開発
2-2-2,ライティング
2-2-2-1,U様案件
2-2-2-2,M様案件
2-2-2-2-1,案件1
3,その他
1列目が階層を表す階層idで、2列目がフォルダ名です。
例えばプライベートフォルダの直下には写真フォルダと動画フォルダが作成され、仕事フォルダの下には本業フォルダと副業フォルダが作成され、さらに本業フォルダの下には開発と社内研修のフォルダが作成され...というようになっています。
ではソースコードを見ていきましょう。
import os
import csv
with open('./folder_name2.csv') as f:
reader = csv.reader(f)
created_folders = {} #キーに階層id、値にフォルダパス
for row in reader:
hierarchy_list = row[0].split('-') #ハイフンで分割し、リストにする
name = row[1]
if len(hierarchy_list) == 1: #1階層目はそのままフォルダを作成する
if not os.path.exists(name):
os.mkdir(f"./folder/{name}")
created_folders[row[0]] = name
continue
# 2階層目以降はすでに作成されたフォルダの下層に作成する
hierarchy_id = "" #階層id
parent_dir_path = "" #親フォルダパス
for number in hierarchy_list:
#既に値が入っている場合はハイフンを付け足す
hierarchy_id += number if hierarchy_id == "" else "-" + number
if (hierarchy_id in created_folders):
#既に作成済の階層のフォルダなら、そのフォルダのパスを設定して次のループに進む
parent_dir_path = created_folders[hierarchy_id]
continue
else:
#新しい階層のフォルダなら、親パスに自フォルダ名を追加してフォルダを作成する
if not os.path.exists(name):
dir_path = parent_dir_path + '/' + name
os.mkdir(f"./folder/{dir_path}")
#作成したフォルダのパスを格納して次の行に進む
created_folders[row[0]] = dir_path
[結果出力]
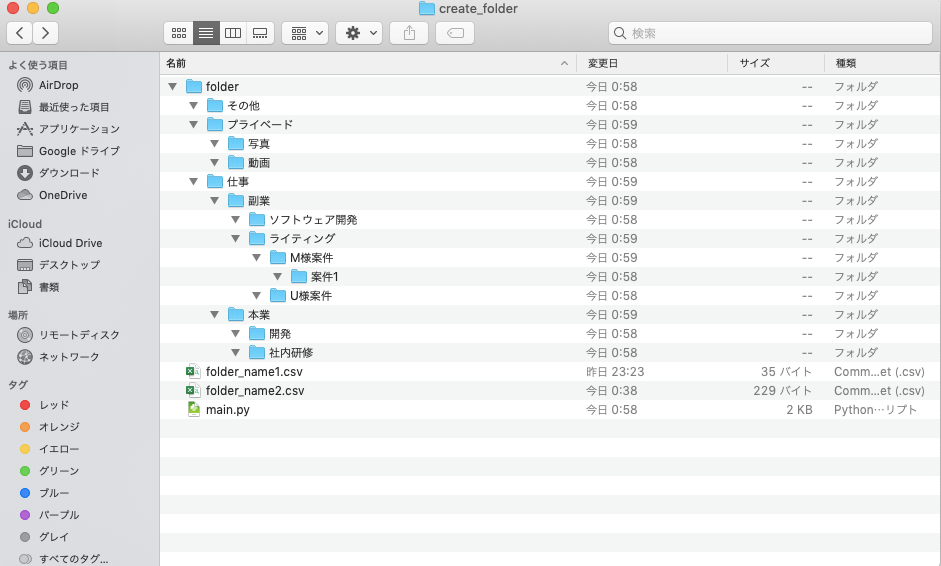
少し長いですが、順を追って見ていきましょう。
6行目のcreated_foldersには作成したフォルダの階層idとそのフォルダのパスが辞書形式で格納されます。
7〜32行目はcsvの行ごとの繰り返し処理で、1回繰り返すごとにフォルダが一つ作成されます。
8行目のhierarchy_listは階層idをハイフンで分割したリストが格納されます。
10〜14行目は単階層のフォルダ作成処理です。作成したフォルダの階層idとフォルダ名をcreated_foldersに格納します(後で作成済の階層かどうか判断するために使います)。
16行目以降は2層目以降のフォルダを作成するための処理です。
19〜32行目は階層のリストごとの繰り返し処理で、1回1回「その階層のフォルダが既に存在するかどうかをチェックし、存在しない場合は新規にフォルダを作成する」という処理を繰り返しています。
1つ目の階層から徐々に深掘りしていき、新しい階層のフォルダになったらその手前の親フォルダのパスに自分のフォルダ名を末端に追加して新しいフォルダを作成しています。
複数のcsvから複階層繰り返しのフォルダ一括作成
最後は複数のcsvから複階層のフォルダを一括作成します。
使うcsvはこちらです。
[.csv/folder_name3.csv]
佐藤
鈴木
高橋
[.csv/folder_name4.csv]
国語
数学
英語
[.csv/folder_name5.csv]
点数
判定
3x3x2で18フォルダ作成されます。
import os
import csv
#target_folderのフォルダのフォルダパスの一覧を取得する
def select_deepest_folders(target_folder):
deepest_folders = []
deepest_depth = 0
for curdir, dirs, files in os.walk(target_folder):
depth = curdir.count('/')
if (deepest_depth < depth):
deepest_depth = depth
for curdir, dirs, files in os.walk(target_folder):
depth = curdir.count('/')
if (deepest_depth == depth):
deepest_folders.append(curdir)
return deepest_folders
files = os.listdir('./csv')
for csv_file in files:
with open('./csv/' + csv_file) as f:
#読み込んだcsvのフォルダ名をリストに格納する
reader = csv.reader(f)
folder_names = []
for row in reader:
folder_names.append(row[0])
#最も深い階層のフォルダの一覧を取得する
deepest_folders = select_deepest_folders('./folder')
#全ての最も深い階層のフォルダの下に読み込んだcsvのフォルダを作成する
for deepest_folder in deepest_folders:
for folder_name in folder_names:
folder_path = deepest_folder + '/' + folder_name
if not os.path.exists(folder_path):
os.mkdir(folder_path)
[出力結果]
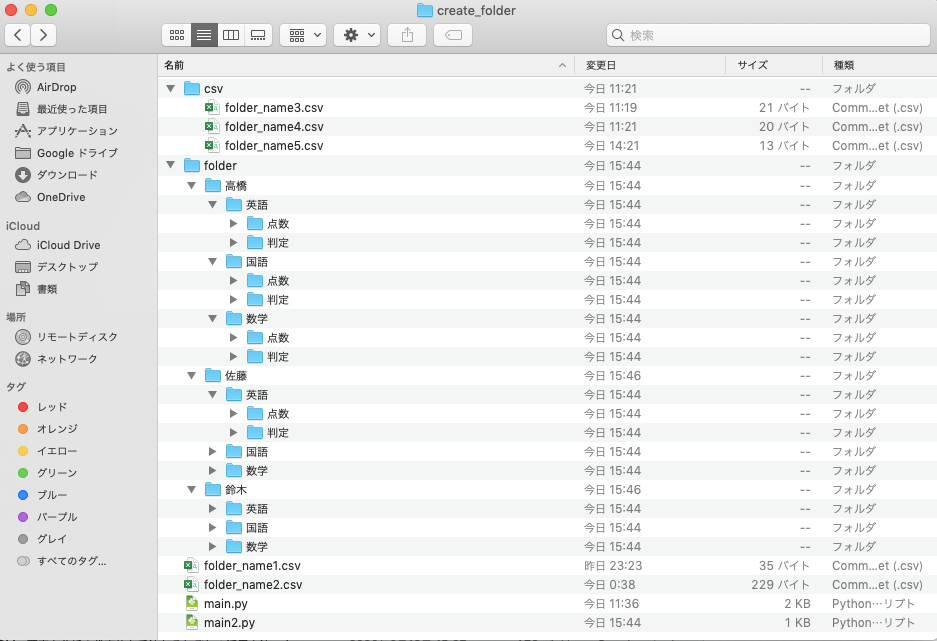
elect_deepest_folders()は対象のフォルダの中で一番深い階層のフォルダの一覧を取得する関数です。
まず1度目のos.walk関数で最も階層の深いフォルダの深さを特定し、2度目のos.walk関数で特定した深さのフォルダ一覧をdeepest_foldersに格納して返却しています。
複数のcsvファイルを使うのでos.listdir()でcsvフォルダ内のcsvファイルを全て取得して繰り返し処理しています。
21〜37行目はcsvファイルごとの繰り返し処理で、1回繰り返されるごとにフォルダ階層が1つ深くなります。
つまりcsvファイル1つに対して階層が1つ増えるイメージです。
次に読み込んだcsvファイルのフォルダ名をfolder_namesに退避し、select_deepest_folders()で現時点の最も深い階層のフォルダを取得しています。
最後に各最深フォルダに読み込んだcsvのフォルダを作っていき、作り終わったら次のcsvファイルの処理へ移ります。



